
无题
Redis
1、Redis简介
redis是一个键值对的数据库。

值不仅可以是字符串,也可以是其他的类型,例如List集合Hash类型等。
从以上存储的数据结构可以看出与传统的SQLServer还是有很大的区别的,没有表,字段等。
像这种键值对结构的数据库我们统称为nosql数据库。
2、什么是NoSql
SQL: 关系型数据库
NoSql非关系型数据库
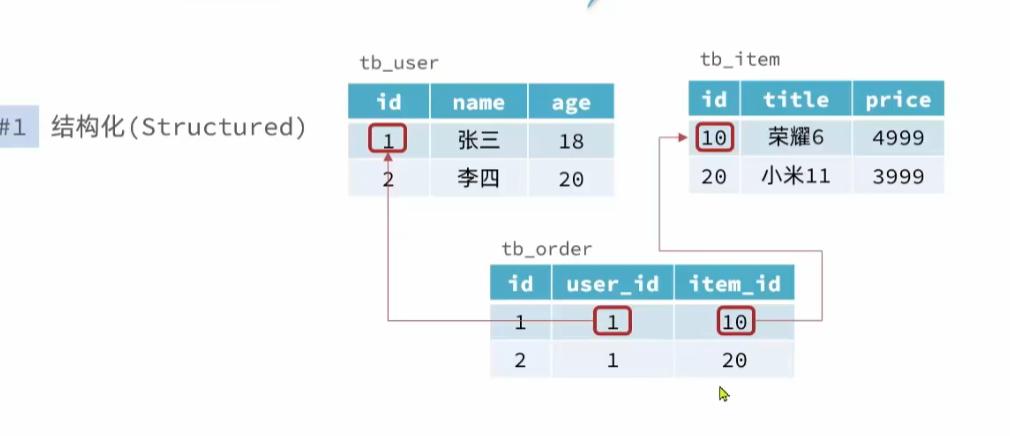
以上图展示的就是关系性数据库中表与表之间的关系。(关联的),这里想删除编号为1的用户或者是编号为10的商品是不允许的。
而NoSql是没有上面这种非常强的关系,那么如果想展示这种关系,应该怎样处理呢?

NoSql是通过一个Josn嵌套的方式来组织对应的关系。

关系型数据库是通过sql语句进行查询,而且大部分的关系型数据库的sql语句基本上是一样的。
而不同的NoSQL查询的语句是不一样的。如下图所示:
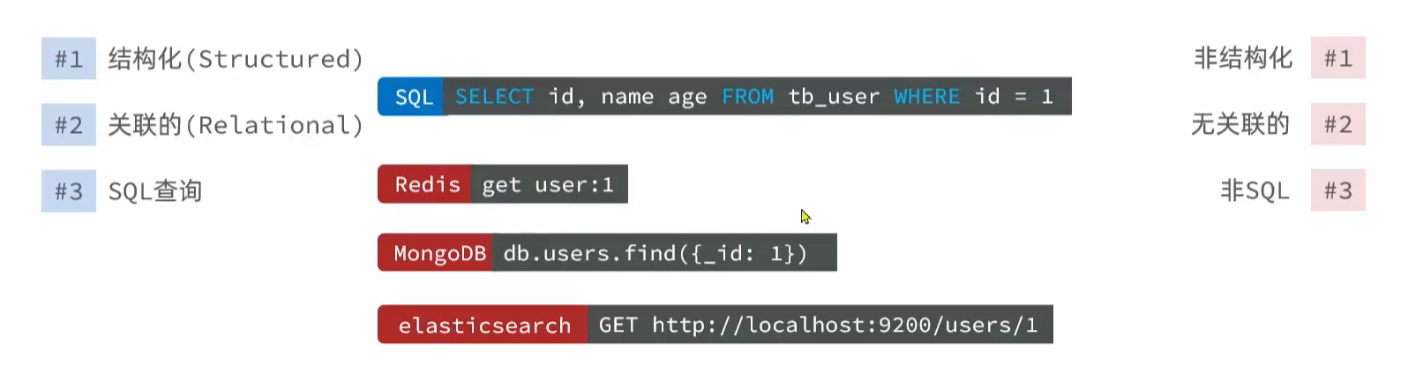
对比Sql语句,NoSql查询语句都比较简单,但是缺点就是使用不同的NoSql数据库需要学习不同的语法。
还有一点不同的是关于事务的处理
sql关系型数据库都有事务的处理,满足ACID特性,但是NOSQL数据库,无法满足事务的ACID,所以你项目要求数据比较安全,就不需要使用Nosql数据库。
关系型数据库是将数据存储到磁盘中,而NoSql是存储在内存中。存储在内存中的好处就是性能非常高,在性能要求比较高的场合都可以使用NoSql数据库。
使用场景:
关系型数据库:(1)数据结构固定,(2)相关的业务对数据安全性一致性要求比较高
这种情况都需要使用关系型数据库。
NOSQL:(1)数据结构不固定,(2)对一致性,安全性要求不高 (3)对性能要求高
当然,在项目中,关系型数据库与NoSQL数据库也可以结合来使用
例如:订单数据是安全性要求较高的数据,需要使用关系型数据库,但是订单是经常查询的为了提升查询的效率,我们又可以将订单的数据在同步到NOsql数据库中。
3、认识Redis

4、安装Redis
windows安装https://github.com/tporadowski/redis/releases
通过以上链接的地址,下载对应的安装包。
下载完以后,进行安装
安装成功,以管理员身份启动cmd
然后通过cd命令,跳转到所安装到的目录。
执行:
1 | redis-server redis.windows.conf |
将redis服务启动起来。
当我们把控制台窗口关闭以后,整个redis服务就停止了,所以我们可以将其作为windows服务来进行安装
1 | redis-server --service-install redis.windows.conf |
1 | win+r |
现在服务端已经启动了,
我们就可以启动一个客户端程序链接服务端程序了。
redis-cli.exe 这是客户端程序
开启一个新的cmd窗口
然后直接输入redis-cli.exe这个命令就可以链接上对应的服务端。
当然,这里我们的服务是安装在本地电脑上,所以显示的ip地址就是127.0.0.1,端口号是6379(默认的端口号)
当然,如果需要链接其他电脑上的redis服务,需要采用如下的链接方式
1 | redis-cli.exe -h 127.0.0.1 -p 6379 |
注意:-h之间是没有空格的。
链接上服务以后,就可以对redis服务进行操作了。
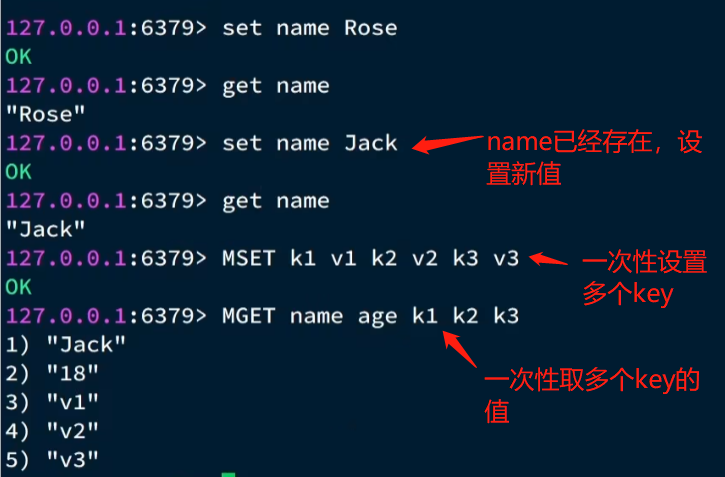
例如:执行set命令来存储数据,set name zhangsan
表示以name表示的就是key,zhangsan就是value,也就是值了。
如果要获取就需要使用get命令
1 | get name |
5、图形化桌面客户端
针对客户端,可以从网上下载免费的图形化桌面客户端,这样操作起来更加的方便。
下载地址:[AnotherRedisDesktopManager 发行版 - Gitee.com](https://gitee.com/qishibo/AnotherRedisDesktopManager/releases)
安装好以后,启动图形化的客户端程序,链接上redis服务端以后,可以看到redis默认16个数据库。
而我们前面存储的key为name,值为zhangsan的这个数据默认是在编号为0的这个数据库,也就是第一个数据库。
现在我们也可以继续向第一个数据库中添加数据,这时候,我们可以通过图形化的客户端添加,也可以通过命令来添加。
现在我们通过图形化窗口向编号为1的数据库中添加了key 为name,值为lisi的数据。
如果,我们向获取应该怎样处理呢?
我们可以在cmd客户端中,通过执行select 1,表示选择编号为1的数据库,然后再执行get name,这时候获取到的值就是lisi
注意:数据库的数量,可以在redis.windows-service.conf这个配置文件中进行调整。
以后,操作redis的时候,可以使用图形化客户端,比较方便,但是在学习的时候,还是使用redis-cli.exe这个客户端。
6、Redis常见命令
Reids是一个key-value的数据库,key一般是string类型,但是value的类型多种多样

在上面的图中列举了value的类型,这里列举了8个,但是还有其他的。这里最常用的就是前5种类型。
注意:Hash类型是一个hash表,这里是通过字符串的形式进行描述
6.1 通用命令
(1)keys命令
1 | keys * // 获取所有的key |
由于keys指令是通过模糊的方式来进行查询,所以当redis中的数据量比较大的时候,查询性能比较慢,由于是单线程,所以在生产的服务器上执行该命令的时候,会阻塞其他命令的执行,所以说在生产服务器上不要使用该命令来查询。
为了后面其他命令的演示,先通过mset命令一次性插入多个key和对应的value
1 | mset k1 aa k2 bb k3 cc k4 dd |
(2) del命令
del命令是删除
1 | del name // 删除key为name的内容 |
del命令返回的结果是一个整数的数字,表示删除的key的数量
(3)exists命令
该命令判断,指定的key是否存在
1 | exists name // 判断name这个key是否存在,如果存在返回的是1,否则返回的是0 |
(4)expire命令
该命令的作用是给一个key设置有效期,有效期到期以后该key会自动的被删除掉。
我们知道redis中的数据默认是存储在内存中的,如果我们不设置有效期,会导致redis中存储的数据量会越来越多。
会导致内存被占满。所以需要expire命令来设置有效期
例如:redis中存储短信验证码,我们可以设置有效期就是5分钟
1 | expire age 20 // 表示age这个key的有效期是20秒钟 |
设置完以后,可以通过
1 | ttl age // 这里通过ttL命令来查看age这个key剩余的秒数 |
如果以上TTL指令输出的值是-2,表示age这个指令已经到期了,然后执行keys *的时候,就查看不到age这个指令了。
1 | set name zhangsan |
我们执行了以上命令,重新创建了一个key是name,并且值是zhangsan
1 | TTL name |
这时候通过TTL来查看name的有效期,发现输出的值是-1,表示name是永久有效。
建议:在redis中,根据实际情况,最好设置key的有效期
6.2 String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型
其中value就是字符串,不过根据字符串的格式不同,又可以分为3类
string:普通字符串
int 整数类型,可以做自增,自减操作(数字型字符串)
float: 浮点类型,可以做自增,自减操作
以上都是字符串,底层都是通过字节数组的形式来进行存储的,只不过编码的方式不同。数值类型的字符串直接转换成二进制后作为字节数组来存储。字符串就是转成成字节码然后再进行存储
字符串类型的最大空间不能超过512M
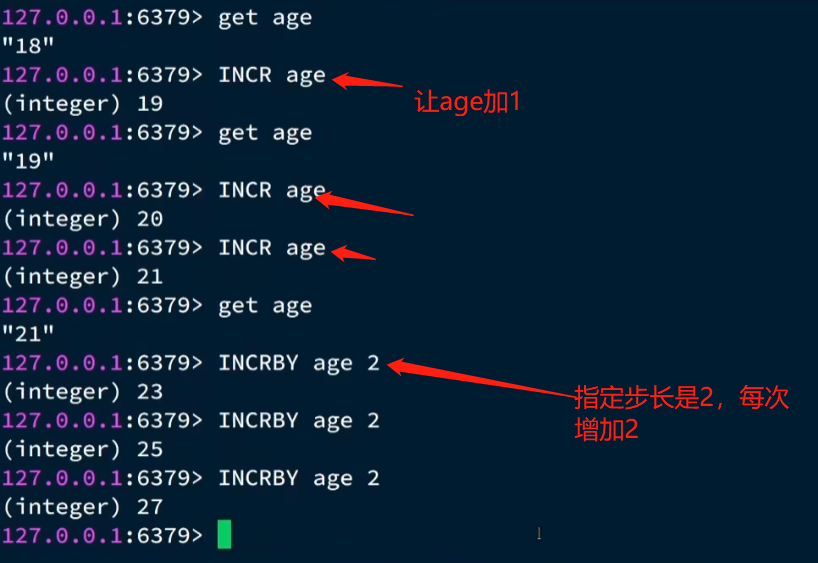
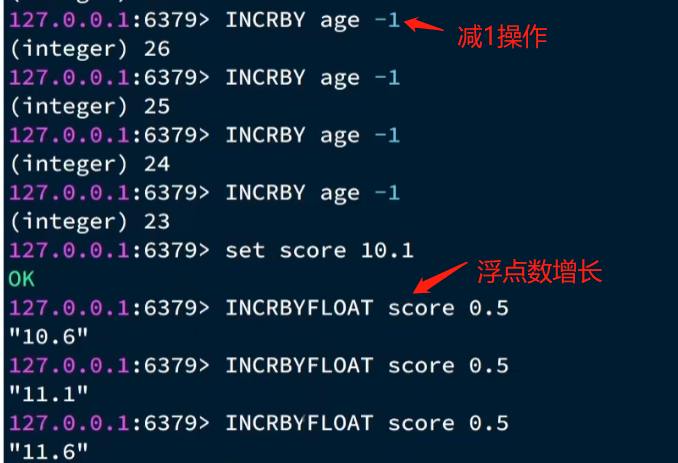
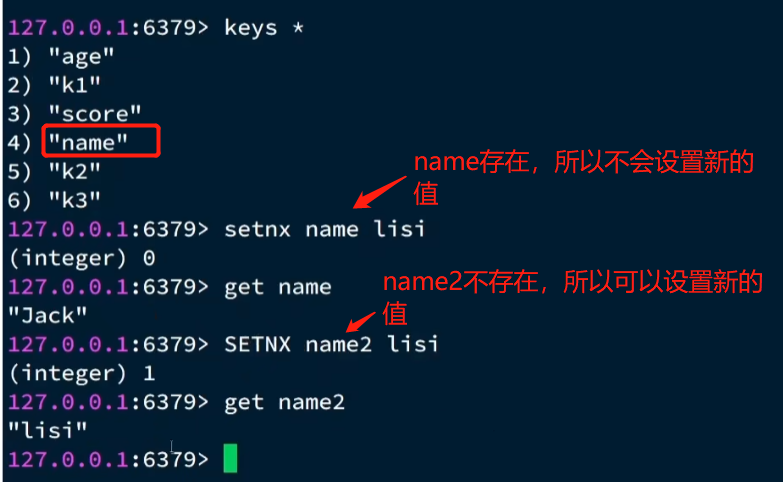
String 常见命令


6.3 Key的层级格式
Redis没有类似MySQL中的Table的概念,我们是如何区分不同类型的key呢?
例如:需要存储用户,商品信息到redis中,有一个用户的id是1,有一个商品的id恰好也是1
都是id怎样区分呢?
我们可以在id的基础上拼接一些其他的字符串来进行区分,当然,这些字符串也不是随便进行区分的。
Redis的key允许有多个单词进行拼接形成层级结构,多个单词之间使用:进行分割。例如以下格式:
1 | 项目名称:业务名:类型:id |
当然,不一定非要按照以上的规则进行拼接,大家根据公司中的实际要求来即可。
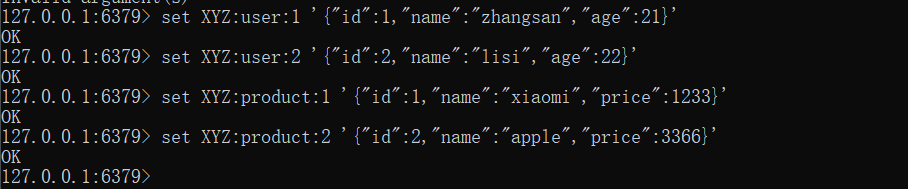
例如:我们的项目名称叫做XYZ,有user和product两种不同的数据类型,我们可以这样定义key
1 | user 相关的key: XYZ:user:1 // 1表示的就是第一个用户的编号 |
以上这是key的定义。
当key定义好以后,怎样存储对应的值呢?
不管是用户也好,还是prodcut,在存储相关的信息的时候,我们一般存储的都是c#对象,问题是对象怎样存储呢?
我们知道c#对象不是字符串,但是完全可以序列化成json格式的字符串来进行存储
如下所示:
执行完以上的命令以后,我们可以看一下对应的图形客户端,如下图所示:
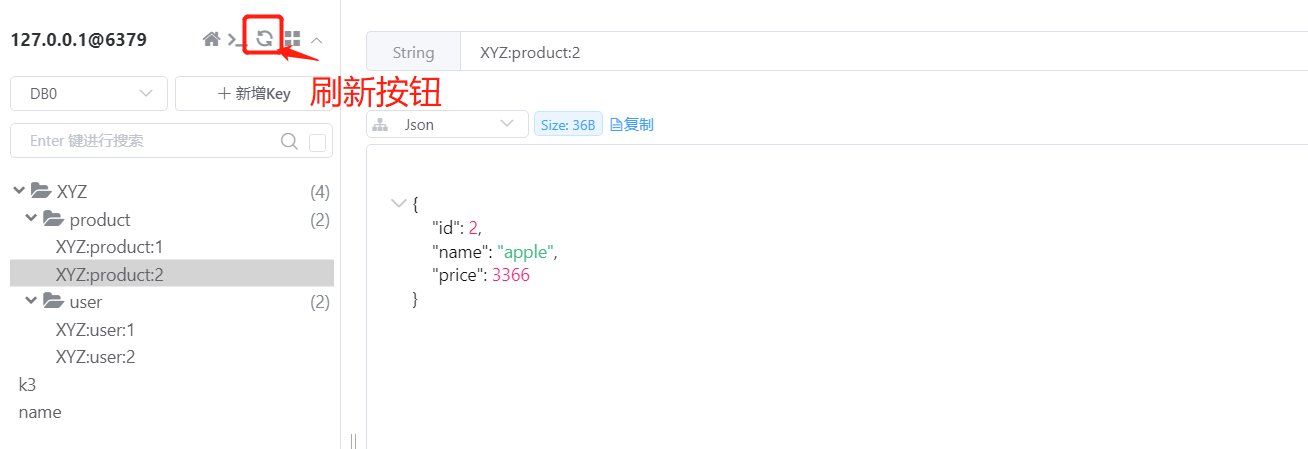
单击刷新按钮以后,可以看到在编号为0的数据库中,存储的内容形成了层级的关系。
6.4 Hash 类型
Hash类型,也叫做散列,其value是一个无序字典
String结构是将对象序列化为JSON字符串后存储,当需要修改对象中某个字段的时候很不方便。
| KEY | Value |
|---|---|
| XYZ:user:1 | {name:”zhangsan”,age:21} |
如果要修改age,只能是将整个字符串替换掉。
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD的操作
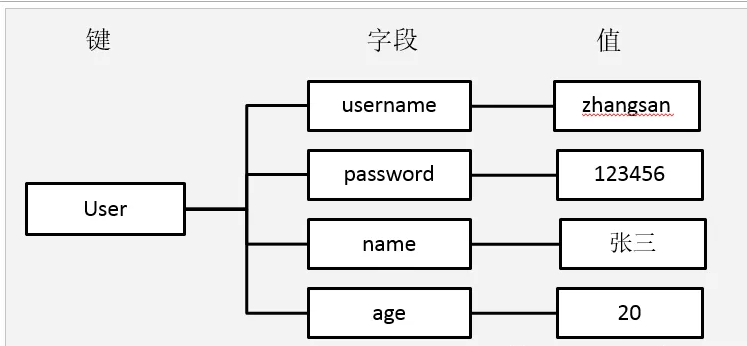


可以返回到图形客户端查看对应的结构。
如果再执行: hset XYZ:user:3 age 22,就是对age这个字段的值进行修改
1 | hget XYZ:user:3 name |
通过hget指令,获取了 XYZ:user:3这个键下面的name这个字段的值。
下面通过HMSET指令进行批量的添加
1 | hmset XYZ:user:4 name wangwu |
这里是通过hmset向XYZ:user:4这个key中添加了name这个字段
1 | hmset XYZ:user:4 name lisi age 20 sex man |
这里是通过hmset指令向XYZ:user:4这个key中添加了name,age,sex这三个字段,并且确定了对应的值。
返回到图形客户端中查看效果
1 | hmget XYZ:user:4 name age sex |
以上是通过hmget这个指令获取XYZ:user:4这个key对应的name.age,sex这三个字段的值。
1 | hgetall XYZ:user:4 |
通过hgetall指令,获取XYZ:user:4这个key中所有的字段,以及字段的值
1 | hkeys XYZ:user:4 |
通过hkeys指令,获取XYZ:user:4这个key中所有的字段
1 | hvals XYZ:user:4 |
通过hvals获取XYZ:user:4这个key中所有的字段的值
1 | hincrby XYZ:user:4 age 2 |
通过 hincrby这个指令,可以让 XYZ:user:4这个key中的age字段的值加2
6.5 List类型
列表(list)类型是用来存储多个 有序 的 字符串。在 Redis 中,可以对列表的 两端 进行 插入(push)和 弹出(pop)操作,还可以获取 指定范围 的 元素列表、获取 指定索引下标 的 元素 等。
列表 是一种比较 灵活 的 数据结构,它可以充当 栈 和 队列 的角色,在实际开发上有很多应用场景。
List类型一般用于对顺序有要求的场景,例如:朋友圈中的点赞功能,点赞是有先后顺序的,还有就是评论,谁先评论的,谁后评论的,这些都是有顺序的数据。


这里首先通过lpush指令,向users这个key表示的列表左侧插入多个元素
可以返回到图形客户端,查看一下users这个key中插入值的顺序是3,2,1。
这里可以想象一下,假如列表中有一个0,执行上面的lpush的时候,先在0左侧插入1,然后是2,最后是3.
同理rpush也是一样的。
1 | lpop users |
lpop表示从users这个key中获取左侧的第一个元素,同时会删除该元素,这里可以返回到图形客户端进行查看。
1 | rpop users |
rpop表示从users这个key中获取右侧的第一个元素,同时也会删除该元素。
1 | lrange users 1 2 |
返回的是1,2这个范围的元素
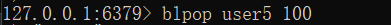
在上面的代码中,通过blpop来获取user5这个key中的内容,等待的时间是100秒。
在这里开启另外一个客户端程序

然后通过lpush添加数据

在等待了47秒以后,获取到了数据。
这就是所谓的阻塞式获取
问题:
第一:如何使用List结构模拟一个栈?
添加数据的时候,通过lpush,取数据的时候通过lpop 模拟的是栈
第二:如何利用List结构模拟一个队列?
lpush添加数据,然后通过rpop获取数据,模拟的就是队列
栈:先进后出
队列:先进先出
6.6 Set类型
集合(set)类型也是用来保存多个 字符串元素,但和 列表类型 不一样的是,集合中 不允许有重复元素,并且集合中的元素是 无序的,不能通过 索引下标 获取元素。
同时支持,交集,并集,差集等功能

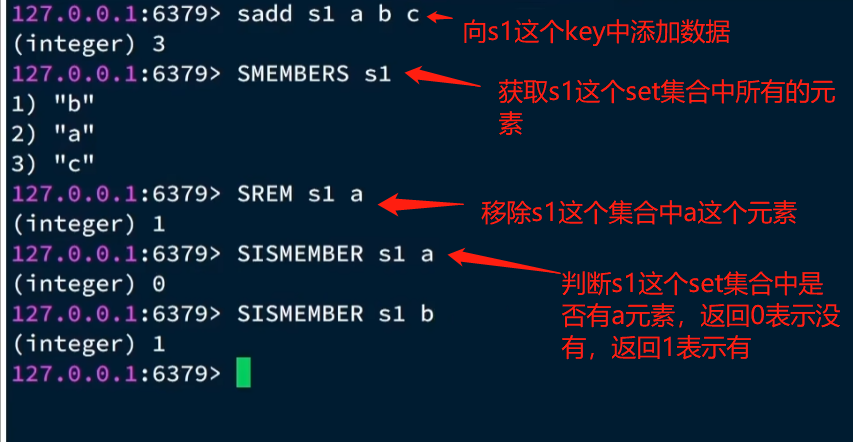

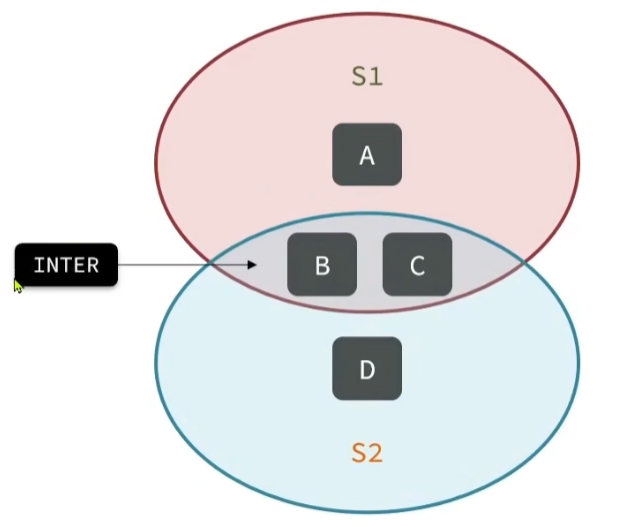

练习:

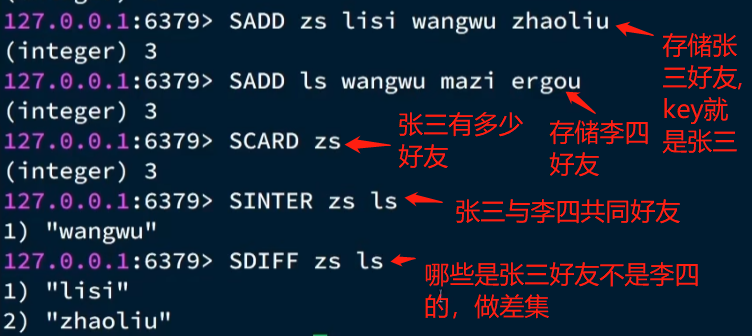
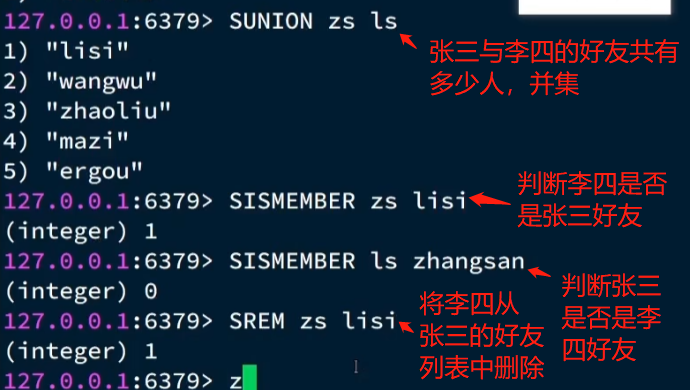
6.7 SortedSet类型
SortedSet是一个可排序的Set集合,SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素进行排序。
因为SortedSet的可排序性,经常被用来实现排行榜这样的功能。

注意:所有的排名默认都是升序的,如果要降序则在命令的Z后面添加REV即可。
练习:


stus表示的是key
数字就是score成绩
名字就是member,也就是成员。
执行完以后,可以看一下图形客户端,发现数据默认都是升序排序的。


1 | ZRANK stus Rose // 升序 |
问题:统计80分以下的学生人数

问题:给Amy同学加2分

问题:查询成绩前3名的同学
注意:这里需要倒序查询(因为默认存储的时候是升序)
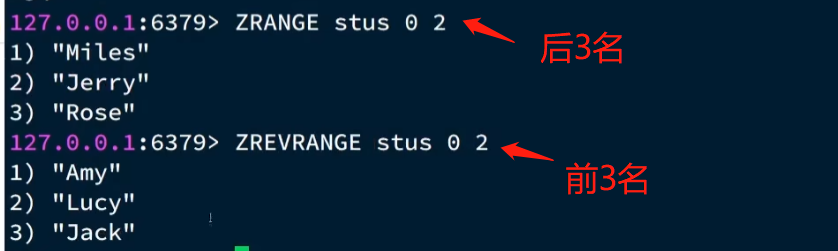
问题:查询出成绩80分以下的所有学生

7、缓存应用
7.1 缓存描述
我们知道redis的性能非常高,所以我们一般会使用redis来做分布式的缓存应用。
Redis官网中提供了各种语言的客户端:https://redis.io/clients
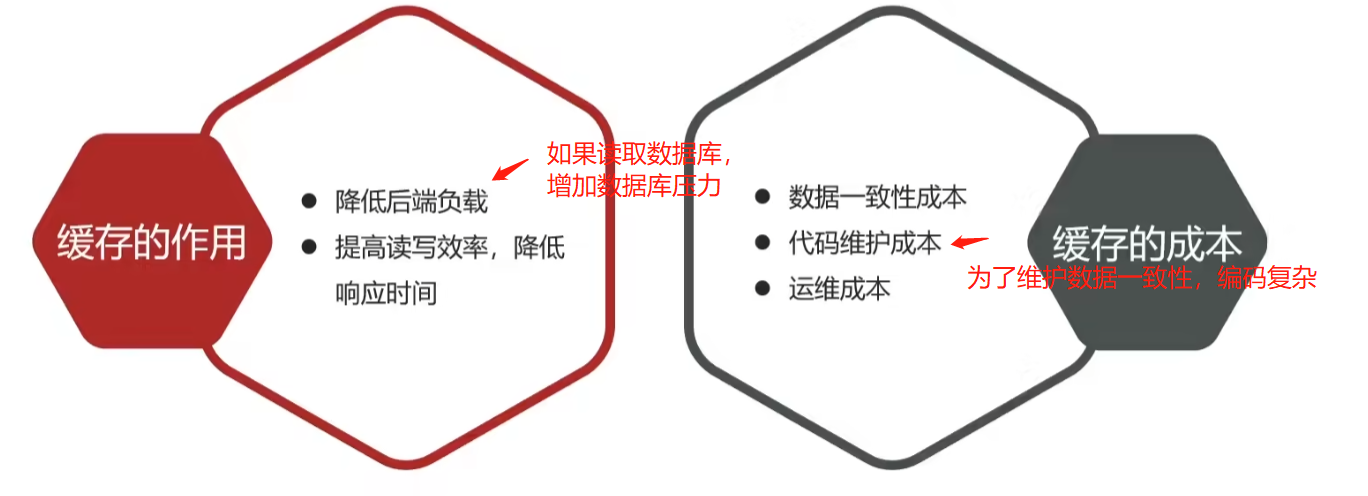
如果用户访问量不大,不使用缓存也是可以的。
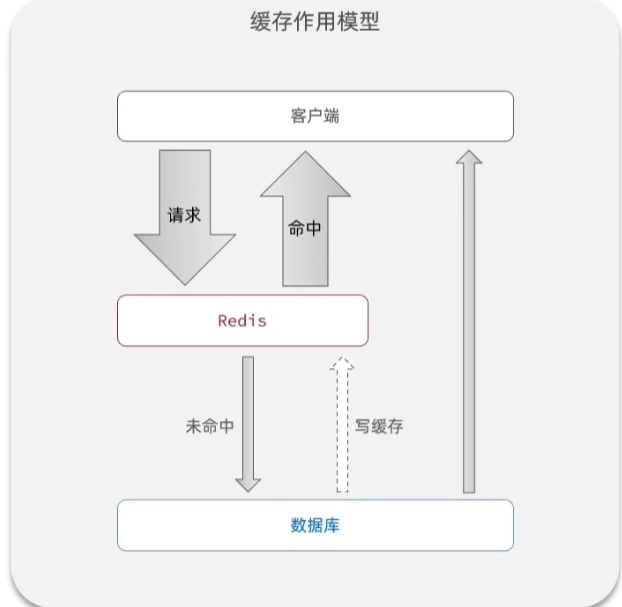
7.2 .Net core中使用Redis
在.Net Core中提供了统一的分布式缓存服务器的操作接口IDistributedCache,用法与内存缓存类似
分布式缓存,由于是在其他的服务器中,与Web应用不是在同一个服务器中,就要设计到网络通信的问题。
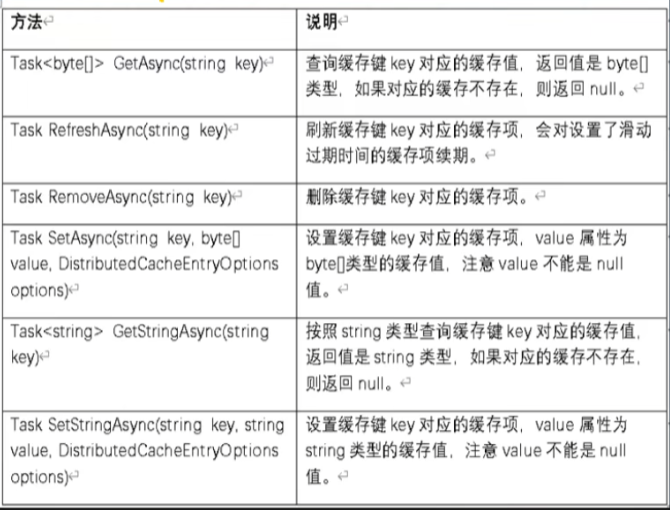
使用方式如下:
新建一个WebApi项目
第一:安装Microsoft.Extensions.Caching.StackExchangeRedis :
Install-Package Microsoft.Extensions.Caching.StackExchangeRedis
第二:注册相关的服务
1 | builder.Services.AddStackExchangeRedisCache(opt => |
创建一个TestsController.cs控制器,该控制器中的代码如下所示:
1 | public class TestsController : ControllerBase |
执行上面的代码以后,查看图形客户端。
7.3 缓存更新策略
当数据库中的数据发生了改变,对应的缓存中的数据也要进行更新,才能保存数据的一致性。
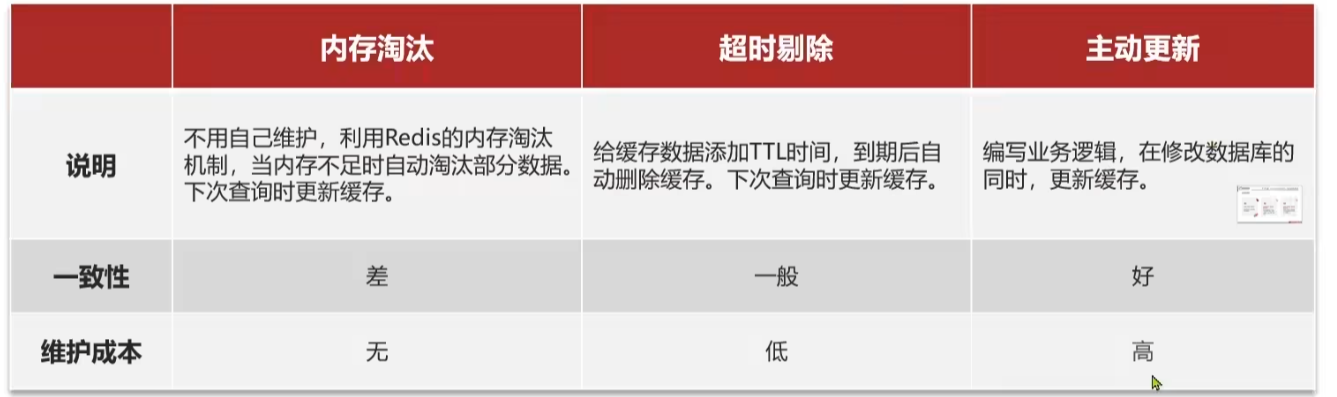
超时剔除:这种更新策略的一致性是一般的,原因是取决于设置的过期时间,如果过期时间设置比较长,对应的用户在这段时间从缓存中获取的有可能还是旧数据,维护成本比较低,就是在添加缓存的时候,指定过期时间就可以了,不需要过多的编码。
主动更新:在更新数据库中的相应数据的时候,顺便更新缓存中的数据,所以相对来讲数据的一致性比较好,但是维护成本比较高,因为,需要我们自己编写更新缓存中数据的代码。
关于主动更新策略,有两种主要使用方式:
第一种方式:由缓存的调用者,在更新数据库的同时更新缓存
第二种方式:调用者只操作缓存,由其他的线程异步的将缓存数据持久化到数据库中,这种方式的好处:例如,我们在缓存中做了10次写操作,而10次完成以后,可以作为一次写操作,将其存储到数据库中。提升了写数据库的效率。
但是这种方式的问题:实现起来比较复杂。
所以第一种方式是首选。
选择了第一种方式以后,还需要考虑如下问题:
举个例子:假如我更新了100次数据库,然后又同时更新了100次缓存,但是在更新的时候并没有人来查这个数据,那么我更新这100次缓存好像也没啥用吧,相当于前99次都是无用功,只有最后一次才是有用的。这就是无效写操作过多的原因。

关于第三个问题:以上两种方式都可以,下面在对这种方式做一个对比,来深入理解一下
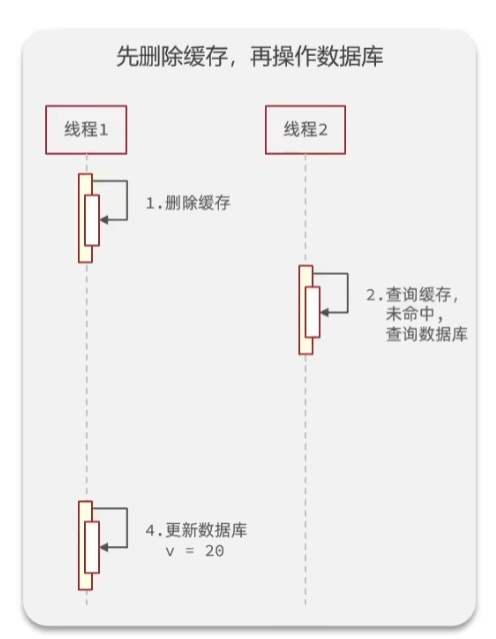
下面先来看一下:先删除缓存,再操作数据库这种情况

缓存和数据库中都存储了10,并且有两个线程。假设线程1更新缓存

这时候线程1,将缓存中的数据清除了

同时线程1将20更新到数据库中
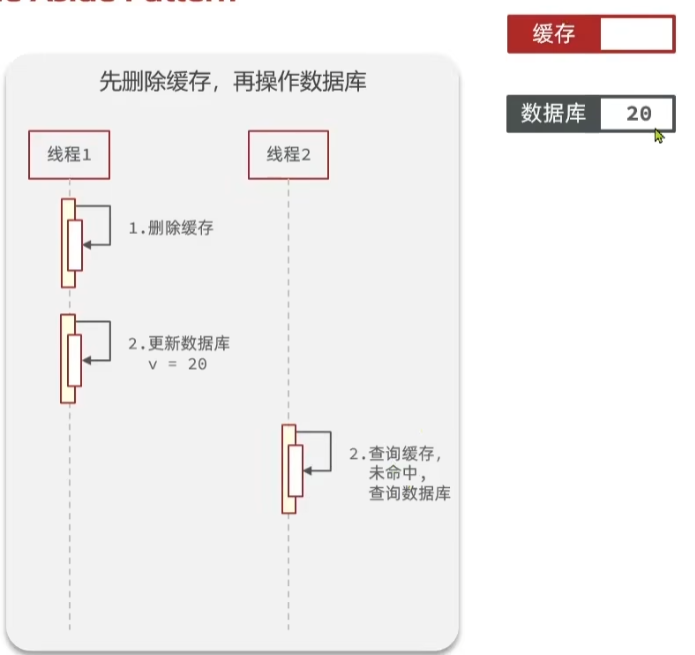
这时候线程2,正好进行查询,这时候查询缓存未命中,直接去查询数据库
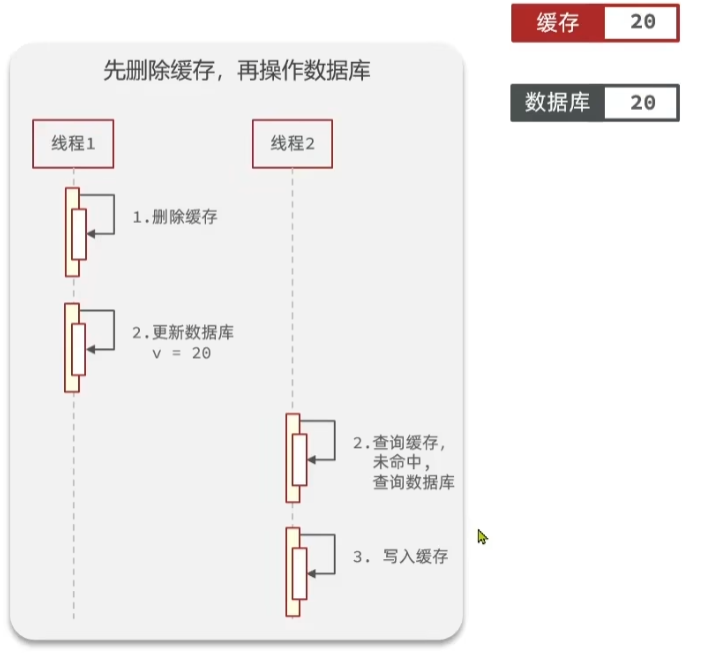
线程2,查询完数据库以后,会将从数据库中查询出的数据写导入到缓存中。
以上情况是正常的情况。
下面我们再来看一下比较特殊的情况。
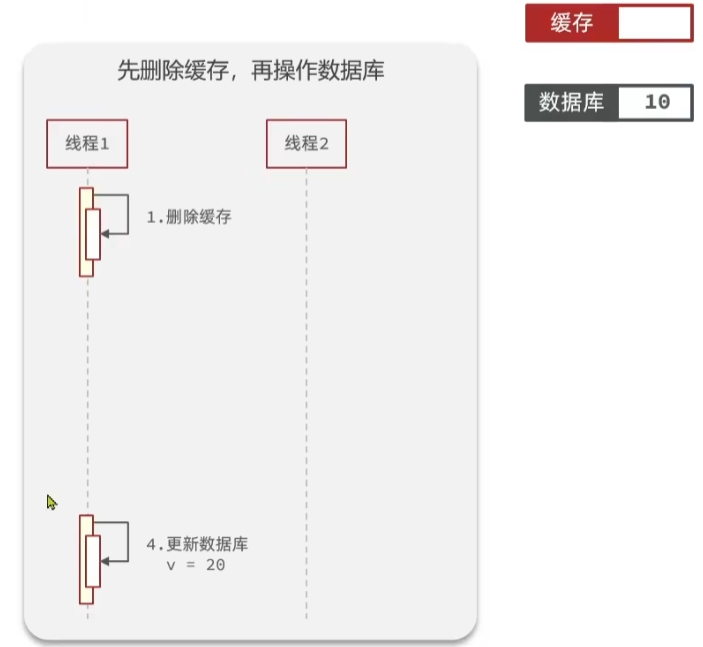
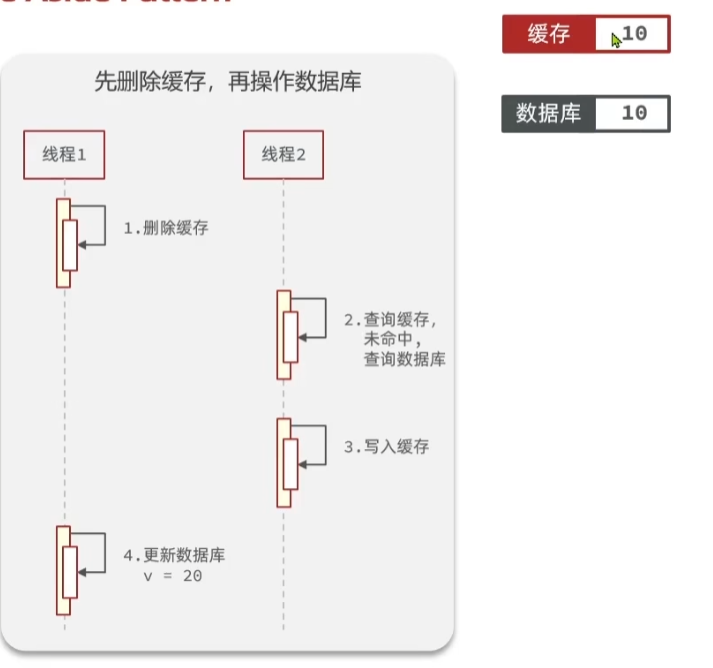
假如,线程1,已经将缓存中的数据删除了,然后去更新数据库,但是更新的业务比较复杂,
这时候正好又来了一个线程2,去查询缓存,但是没有被命中,只能去查询数据库,这时候查询出来的是数据库中旧的值。
同时还要把数据写入到缓存中,但是这时候写入到缓存中的数据也是旧的值,如下图所示:
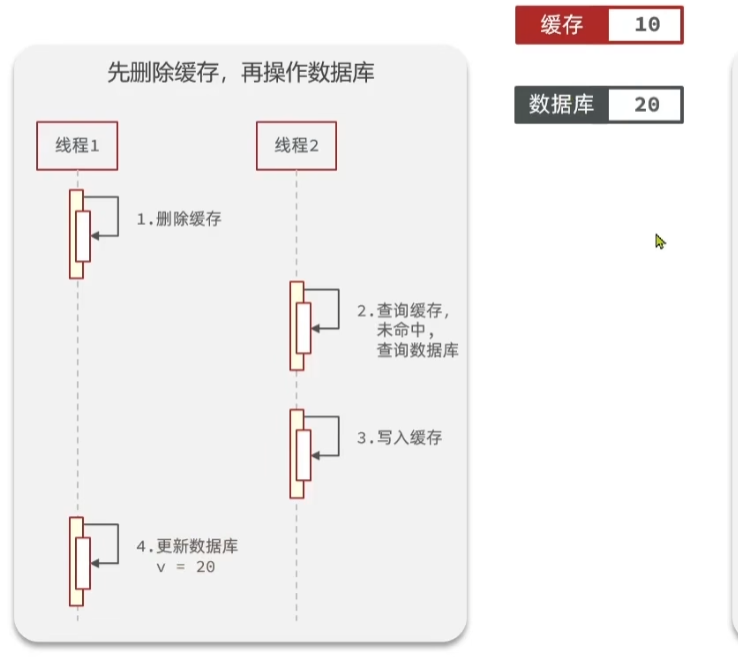
这时候,线程1更新数据库的操作完成了,这时候数据库中的值是20,但是缓存中的值是10。
这时候,数据库和缓存中的数据就不一致了,这就是多线程安全问题。
下面我们再来看一下:先操作数据库,再删除缓存的情况
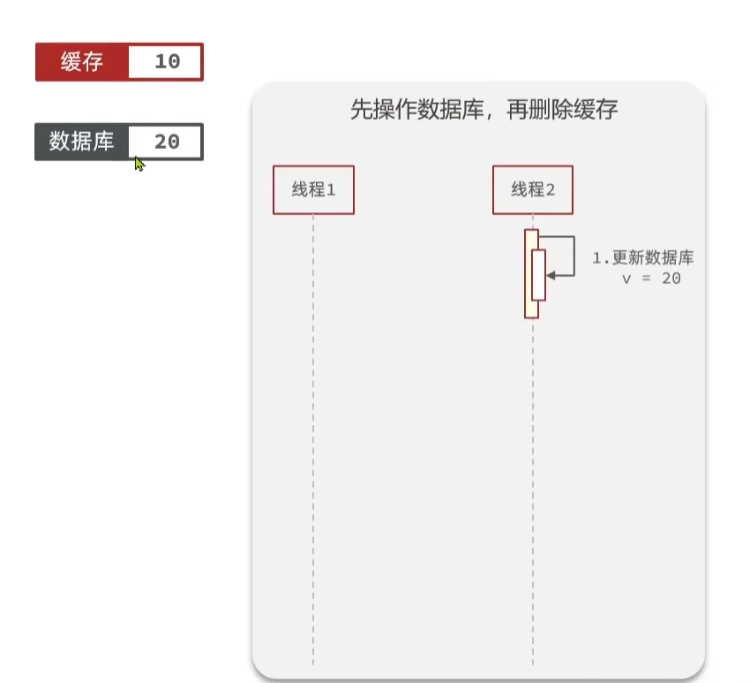
在上图中,假设线程2,先更新数据库,这时候数据库中存储的值是20,缓存中存储的是10.
线程2,更新完数据库以后,紧接着会删除缓存,这时候缓存中的数据没有了。
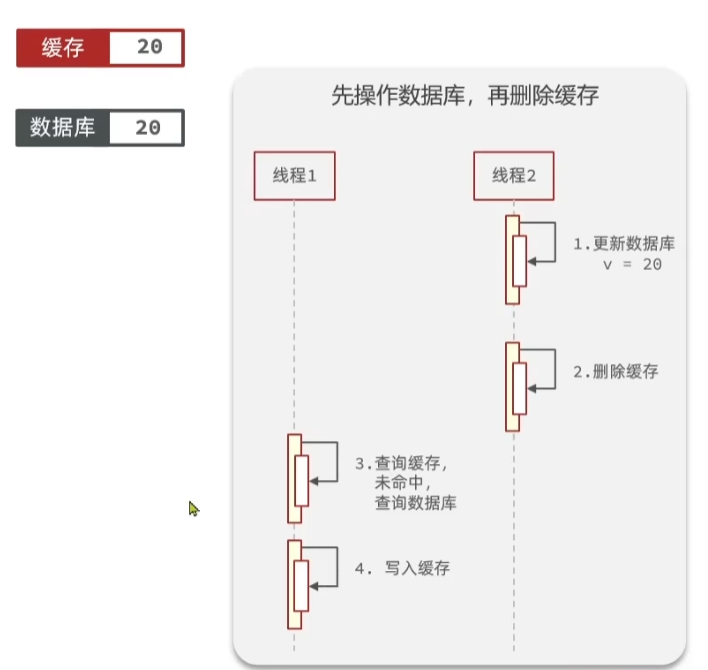
这时候,线程1来查询缓存,但是没有命中,只能去查询数据库,然后在向缓存中写入数据。这时候,缓存中的数据是最新的。
以上是正常的情况,下面再来看一下特殊的情况
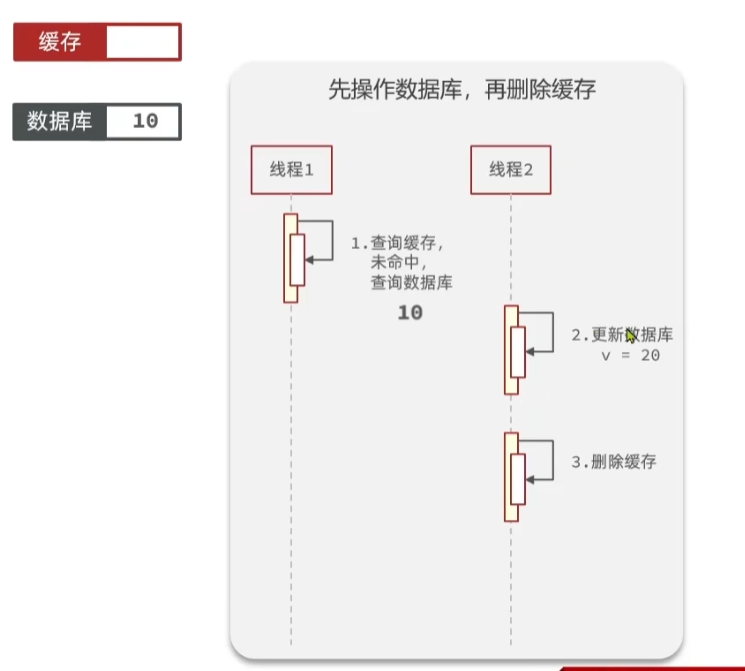
现在假设缓存中没有数据,线程1,查询缓存没有命中,查询数据库,得到的数据是10
这时候线程2更新数据库,将数据库中的数据修改成20,如下图所示
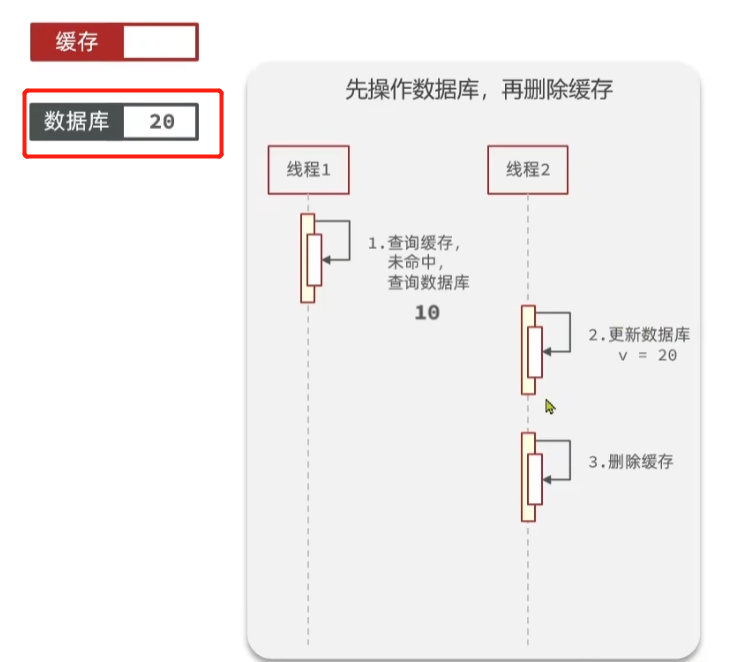
更新完数据库以后,删除缓存,但是缓存中本来就没有数据,所以这次操作什么都没有做。
这时候,线程1,开始写缓存。如下图所示:
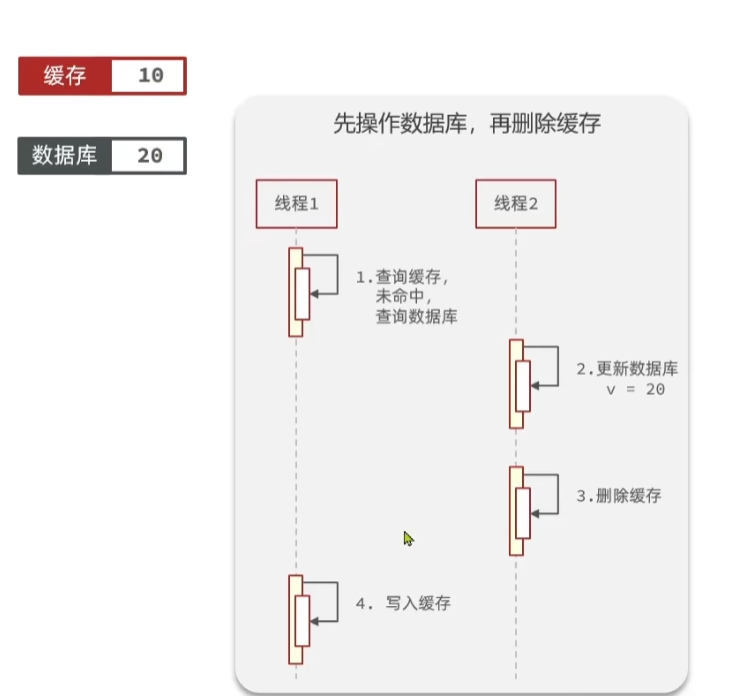
这时候,向缓存中写入的数据是线程1最开始查询出来的旧数据,也就是10,这时候缓存中的数据就是10.
从而导致了缓存与数据库中的数据不一致的情况。
问题是:这种先操作数据库,再删除缓存的操作发生的概率大吗?
相比于【先删除缓存,再操作数据库】这种情况来讲,要小的多。
因为在线1完成了第一不操作以后,再到第四步操作,所需要的时间,比线程2 完成第二步操作和第三步操作需要的时间相对来讲要短。
所以,推荐使用【先操作数据库,再删除缓存】这种方式。当然,这种方式也会出现意外情况,为了避免这种情况,我们可以再添加上超时剔除作为兜底的方案。我们可以在写入缓存的时候,添加超时时间,这样即使写入了旧数据,到了指定的时间,缓存中的数据也会失效。
7.4 缓存更新策略应用
需求1:根据id查询图书的信息,如果缓存没有命中,则查询数据库,将数据结果写入到缓存中,并设置超时时间。
修改TestsController.cs中的代码,在该控制器中添加了Test2方法,代码如下所示:
1 | [] |
以上Test2方法中的代码与前面所写的Test方法中的代码基本上是一样的,这里只不过添加了过期时间。
1 | 如果想设置缓存过期时间则通过DistributedCacheEntryOptions,它可以设置滑动过期时间(SlidingExpiration)、绝对过期时间(AbsoluteExpiration)和相对于现在的绝对过期时间(AbsoluteExpirationRelativeToNow)。 |
执行完上面的代码以后,查看图形客户端,重点查看key中的表示过期时间的字段
需求2:根据id修改图书信息,先修改数据库,再删除缓存
1 | [] |
在测试上面的代码的时候,查看一下图形客户端,看一下那个编号的图书是存储在redis中的,在测试的时候就输入对应的编号。
这样可以看到对应的编号的书的价格修改了,同时缓存也被删除了。
7.5 缓存穿透
缓存穿透:指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案:
缓存空对象
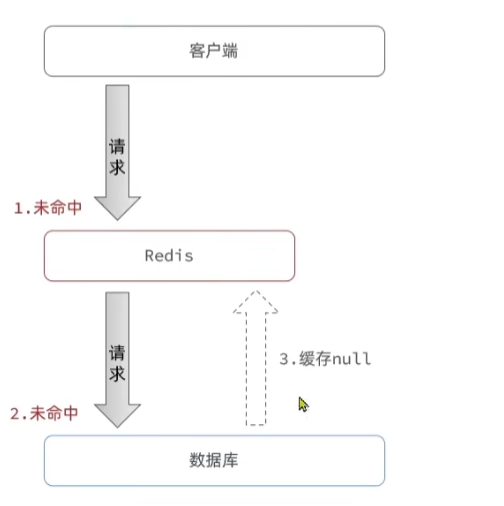
客户端请求redis,redis中没有对应的数据,这时候会请求数据库,数据库中也没有对应的数据。
这时候会将空值缓存到redis中,下次请求的时候,就会被命中,只不过这时候得到的是空值。
例如:请求编号为100的书,缓存中没有,请求数据库,数据库中也没有编号为100的图书信息,这时候,会在redis中存储一个编号100为key对应的值是空值,下次再请求编号为100的图书,直接从redis中返回空值。这时候不会再请求数据库了。
这种方式的优点就是:简单方便
缺点:会造成一定的内存消耗,例如:用户随意请求了很多不存在的编号,这样redis中就缓存了很多的null,这就会造成一定的内存资源的浪费,当然为了解决这个问题,我们可以设置过期时间。这样就可以解决内存资源浪费的问题。
还有一点就是,这种方式有可能造成短期数据不一致的情况,例如:用户请求了编号为100的图书,缓存中不存在,数据库中不存在,这时候redis缓存了编号100对应的值就是空值,而且假设缓存设置的过期时间是5分钟,在这时候,管理员恰好录入了编号为100的图书,而其他用户请求编号为100的图书的时候,在5分钟内得到的结果还是空值。
当然,这里我们可以使用我们前面介绍的方式来解决这个问题,就是再向数据库中添加图书的时候,顺便更新对应的缓存。
具体代码实现,如下所示:
1 | [] |
启动项目,可以打上断点进行测试。
当然,为了防止缓存穿透,除了上面提到的方法,还可以增强id的复杂度,避免被猜测出id规律。
同时进行权限校验,不是所有的方法,用户都可以请求
7.6 缓存雪崩
缓存雪崩:是指在同一时间段大量的缓存key同时失效或者redis服务宕机,导致大量请求到达数据库,带来巨大的压力。
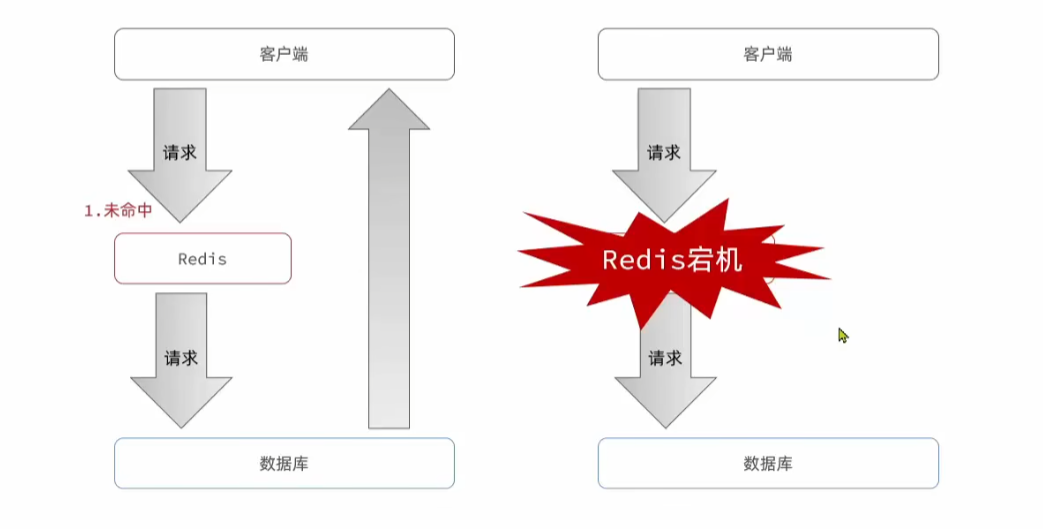
针对大量缓存过期的问题:
实际应用中,我们一般都是提前把数据库中的数据导入到redis缓存中,这样就会导致,导入数据的过期时间是一样的。
所以就会出现在同一时间段大量缓存过期的情况。
针对这种情况的处理,我们一般就是给不同的Key的过期时间在加上一个随机的值。例如:10–20分钟之间的随机值,这样就不会导致在同一时刻大量缓存过期的情况。(这个大家可以自己编码)
针对Redis宕机的情况,一般的解决方案就是利用Redis集群提高服务的可用性。
7.7 缓存击穿问题分析
缓存击穿问题:也叫做热点Key问题,就是一个被高并发访问并且缓存重要业务数据的 ,较复杂的Key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
简单理解:缓存击穿问题常见的是两种情况
第一种情况:就是一个缓存的Key访问非常频繁,但是如果这个缓存失效了,就有可能给数据带来巨大的压力。
第二种情况:我们知道,当缓存失效后,会查询数据库,但是有的情况把数据从数据库中查询出来以后,并不是立即写入缓存,因为有可能还需要进行一些其他的业务处理操作,而这些业务的处理有可能需要时间比较长,在这一个比较长的时间段内,redis中是没有缓存对应的数据的,而这时候恰好有很多请求,这时候只能请求数据库。
针对缓存击穿的问题,我们可以通过【互斥锁来解决】
如下图所示:
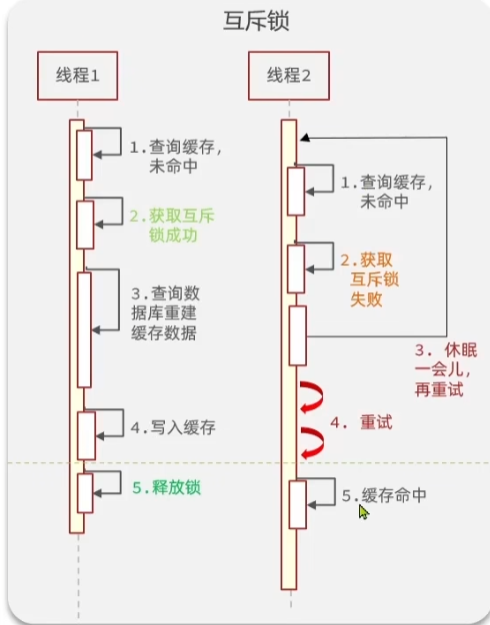
线程1,没有从缓存中查询到数据以后,会得到一个锁,这时候开始查询数据库,进行数据的处理,当然这个过程有可能业务比较复杂,需要等待一段时间,而这时候线程2发来请求,发现缓存中没有数据,这时候线程2也会尝试获取互斥锁,但是这时候线程2获取失败了,在等待了一段时间后,会再次查询缓存,重新尝试获取互斥锁。不断重复这个过程。
直到线程1,把数据写入到缓存,释放了锁以后,线程2在查询缓存的时候,才会获取到缓存中最新的数据。
这种互斥锁相对比较简单,但是问题是性能比较低。
假如有1000个线程,也就是1000个请求者,这时候只有1个线程获取到了互斥锁,并且在处理的过程中比较耗时,这时候剩余的线程只能进行休眠,重试的过程,也就是等待的过程。
7.8 利用互斥锁解决缓存击穿问题
业务的流程如下图所示:
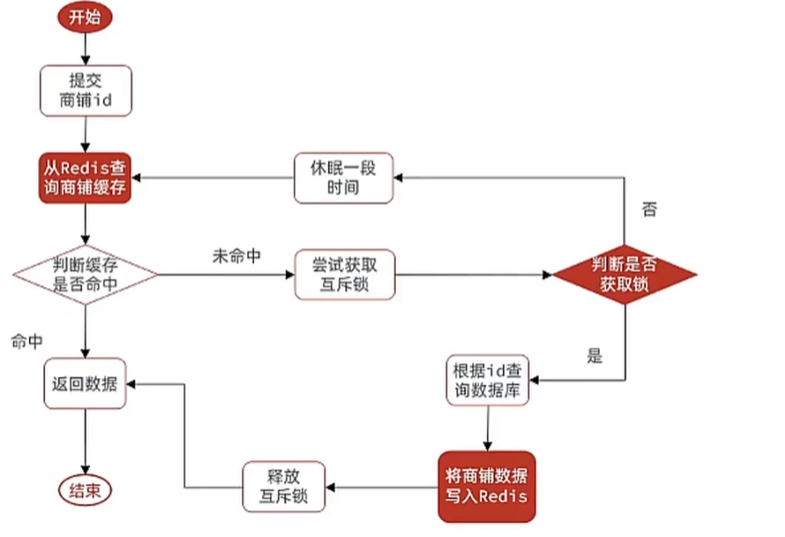
关键是这个锁怎样确定呢?
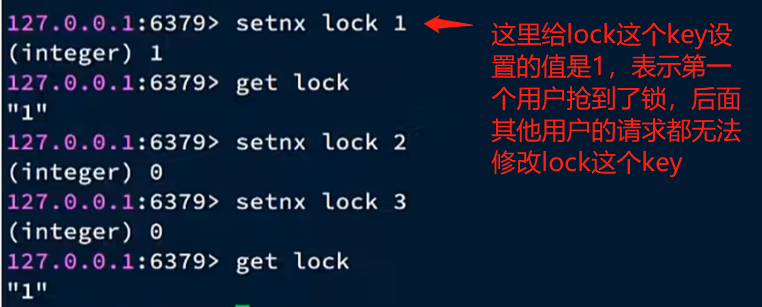
这里我们可以通过setnx方法来实现,这个方法我们前面也介绍过,在设置字符串的key的时候,会做检查,如果key不存在,才会给指定的key设置值,如果存在,则不做任何更改。
怎样释放锁呢?
1 | del lock |
就是通过del把lock这key删除掉旧可以了。就相当于释放了锁。
这里有一个问题就是:假设线程1获取到锁了以后,进行其他的业务处理,但是在处理的过程中出现了异常,有可能就会导致锁无法释放,所以为了避免这种情况的出现,我们可以在创建锁的时候,指定过期时间。
下面修改TestsController.cs控制器中的代码,如下所示:
1 |
|
下面创建一个新的方法Test5,代码如下所示:
1 | /// <summary> |
注意上面的业务逻辑步骤1,2,3,4,5, 关于第4步与以前是一样的,不做代码上的修改。
启动程序进行测试,可以查询编号为1的图书,当然redis缓存中不能有编号为1图书的信息。
然后打上断点,查看代码的执行流程。
7.9 封装分布式缓存操作的帮助类
先创建一个Common类库项目,在该类库项目中进行帮助类的封装。
首先安装对应的包
1 | <ItemGroup> |
创建IDistributedCacheHelper.cs接口,该接口中的代码如下所示:
1 | public interface IDistributedCacheHelper |
创建实现上面接口的类DistributedCacheHelper.cs(这里解决了缓存穿透,缓存雪崩问题,但是缓存击穿没有添加,大家可以自行更改)
1 | using Microsoft.Extensions.Caching.Distributed; |
同时在Common这个类库项目中,创建一个RandomExtensions.cs类,该类扩展Random
代码如下所示:
1 | namespace Common |
在WebApi项目中引用Common项目
然后在Program.cs文件中,将DistributedCacheHelper这个帮助类添加到容器中
1 | builder.Services.AddStackExchangeRedisCache(opt => |
修改TestsController.cs控制器中的代码,如下所示:
1 | public class TestsController : ControllerBase |
下面再控制器中创建对应的方法进行测试,代码如下所示:
1 | [] |
启动程序进行测试。