
Entity Framework Core
Entity Framework Core
Entity Framework Core(简称EF Core)是.Net Core中的ORM框架,它可以让开发人员以面向对象的方式进行数据库的操作,从而大大的提升了开发的效率。
1、什么是ORM?
ORM(object relational mapping,对象关系映射).
对象:指的就是C#中的对象,而“关系”指的就是关系数据库,“映射”:指的就是在关系数据库和c#对象之间搭建一座桥梁,能够让对象模型与关系数据库的表结构之间进行相互转换。我们知道,在.Net中可以通过Ado.net链接数据库然后执行SQL语句来从操作数据库中的数据。而ORM可以让我们通过操作C#对象的方式来操作数据库,比如,使用ORM,可以通过创建C#对象的方式把数据插入到数据库中,而不需要编写Insert语句。如下伪代码所示:
1 | UserInfo userInfo = new UserInfo(){UserName="laowang",Password = "123"}; |
当然,如果想进行查询,可以使用如下方式:
1 | UserInfo userInfo = orm.UserInfo.Single(u=>u.id > 2 || u.UserName.Contains("wang")) |
通过以上的伪代码,我们可以看到,这里直接写一个linq查询就可以了,不用写select 查询的SQL语句,非常简单,ORM框架会将其转换成对应的SQL语句。
在这里我们还需要注意的一点就是:**Entity Framework Core 这个ORM框架只是对ADO.NET的封装,ORM底层仍然是通过ADO.NET访问数据库的。** Dapper
EF Core是微软官方推出的ORM框架。EF Core不仅可以操作SQLServer数据库,还可以操作MySQL,Oracle等数据。除了EF Core这个ORM框架之外,在.Net Core中还可以使用Dapper,NHibernate Core等第三方的ORM框架。但是由于EF Core是微软官方推出的,并且EF Core体现的是面向对象模型的编程方式,更加先进,所以EF Core的市场占有率比较高。
1.1 开发思想的转变
以前,开发项目,调研完需求以后,就开始设计数据库。
但是现在的主流开发方式是先分析业务,然后设计模型,并且指定模型之间的关系,最后在生成对应的数据库。
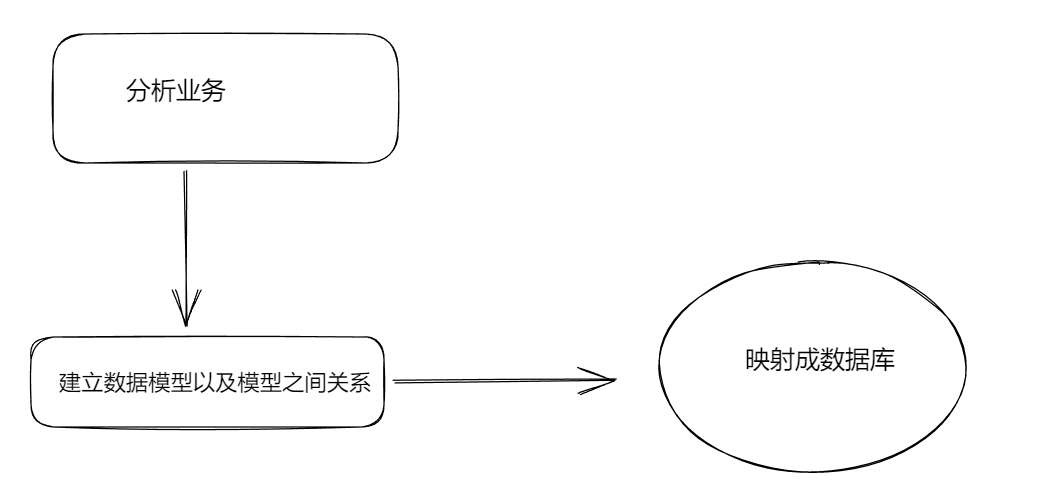
什么是业务呢?
例如:对大家比较熟悉的购物网站来说,最关键的业务就是,搜索商品,展示商品,用户登录,下订单购买。
当然,这里还可以针对以上的业务最进一步的划分。
例如:针对网站的管理员,可以发布商品,修改商品的信息,删除商品信息。
针对老用户可以进行登录,那么针对新用户就必须提供注册的功能,
用户登录以后,可以将商品放入购物车,当然也可以将购物车中的商品删除,最后进行支付。
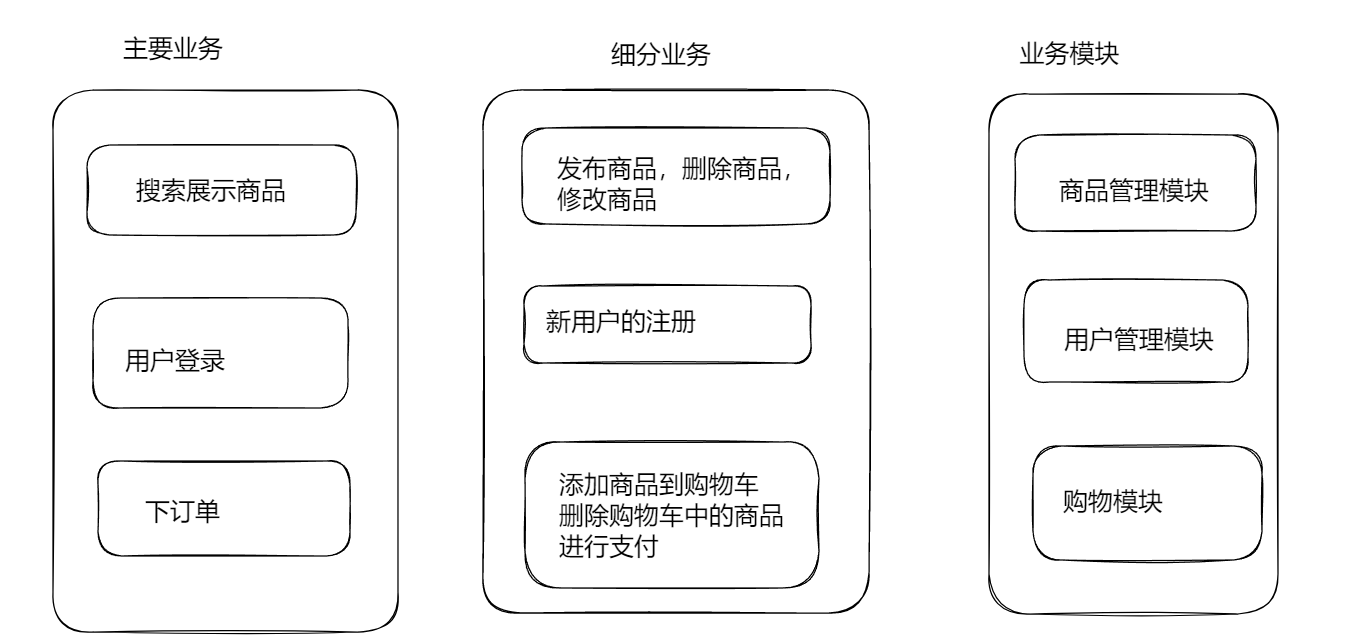
下面,我们就可以针对上面的三个模块进行数据模型的设计。
什么是数据模型?
数据大家都理解。
所谓的模型就是总结事物的规律。使用这个规律来定义这个事物,所以说模型就是一种可以描述复杂事物的一种方式方法。
例如:描述一下苹果,也就是给苹果建模。
我们可以通过【化学成分】来描述苹果,也可以通过【味道】来描述苹果,还可以通过【外貌特征】聊描述苹果。
以上不同角度的描述都是正确的,问题是我们应该选择哪一个角度来描述苹果呢?
这就需要结合业务来分析了。
如果是化学家,需要通过化学成分这个角度来描述苹果(建立苹果的化学成分的模型),如果是摄影师就需要通过外貌特征来描述苹果,如果是美食家就需要通过味道来描述苹果。
针对上面我们提到的业务,我们应该怎样进行描述,也就是怎样进行建模呢?
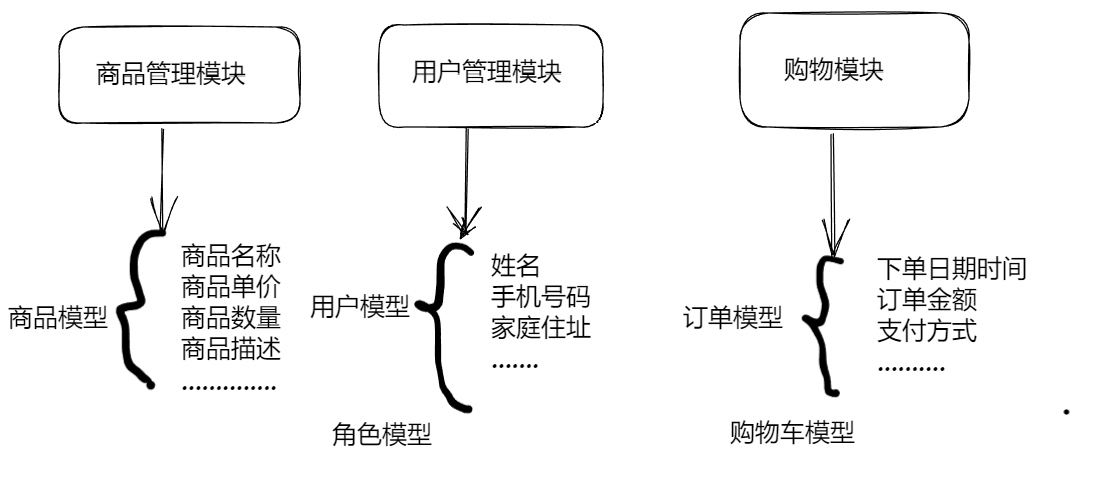
下面就可以建立关系了:用户与角色是多对多,用户与购物车是1对1关系,用户与订单是1对多也就是一个用户可以下多个订
以上就是我们常说的基于模型驱动的开发,而不是数据库驱动的开发。
2、EF Core性能问题
关于EF Core有的人认为性能比较差,给出的解释是:EF Core是把C#对象的操作转换成SQL语句,由于SQL语句是自动生成的,所以说EF Core就可能会产生性能比较低的操作。这是很多人认为“EF Core”性能差的原因。
但是这种说法是错误的。
具体的原因:
第一:如果开发人员对EF Core有了比较深入的了解以后,也是可以写出性能比较高的代码,而且”EF Core“也提供了性能优化的相关功能,可以帮助开发人员对程序进行性能优化。
第二:EF Core也可以直接执行SQL语句,这样在一些性能瓶颈的环节,或者说需要写复杂的SQL语句的应用场景,开发人员仍然可以直接编写优化后的SQL语句。
非常重要的一点是,我们使用EF Core进行开发的效率是非常高的,比手写SQL语句能更快地完成代码的编写。在进行系统开发的时候,程序的运行效率并不是唯一的考量因素,我们需要综合考虑性能、开发效率、可维护性等多个维度的因素。使用EF Core可以帮助开发人员更快地完成项目,这就是非常大的优势;对于性能瓶颈环节,开发人员可以再使用EF Core进行优化;对于使用EF Core优化后性能还较差的环节,开发人员还可以把EF Core代码改为直接执行SQL语句.这样我们就可以在开发效率和程序运行效率之间做好平衡。
3、EF Core基本使用
前面我们讲过EF Core支持所有主流的数据库,包括Microsoft SQL Server、Oracle、MySQL等。
但这里我们主要使用的还是SQL Server.因为Microsoft SQL Server是微软自己的产品,因此EF Core对Microsoft SQL Server的支持非常全面,bug也非常少,有一些新特性只有在Microsoft SQL Server中才支持。当然Microsoft SQL Server服务器的成本是相对比较高的,因此对于成本敏感的项目,也可以使用MySQL等数据库。无论用哪种数据库,EF Core的用法几乎是一模一样的。
下面我们就来看一下EF Core的基本使用
EF Core用于将对象和数据库中的表进行映射,因此在进行EF Core开发的时候,需要创建C#类(也叫作实体类)和数据库表两项内容。在经典的EF Core使用场景下,由开发人员编写实体类,然后EF Core可以根据实体类生成数据库表.所以这里我们也采用这种开发方式。
这里我们做的案例通过向数据库中添加一本书。
第一步:先新建一个控制台的项目,在该项目中创建一个Book实体类、代码如下所示:
1 | public class Book |
第二步:为项目安装NuGet包Microsoft.EntityFrameworkCore.SqlServer
1 | Install-Package Microsoft.EntityFrameworkCore.SqlServer |
我们先创建一个实现了IEntityTypeConfiguration接口的实体类的配置类BookEntityConfig,它用于配置实体类和数据库表的对应关系.
1 | namespace ConsoleApp |
IEntityTypeConfiguration接口是一个泛型的接口,这里我们指定的泛型参数类型是Book这个实体类,表示对该实体类进行配置,然后在所实现的Configure这个方法中对Book这个实体类与数据库中的表之间的关系做详细的配置。其中 builder.ToTable("T_Books")这行代码表示的是Book这个实体类对应的是数据库中的T_Books这张表(表的名称可以根据自己的习惯随意的定义)。
当然,这里有同学可能会想?数据表中是有字段的,而且每个字段都是有类型的,但是这里我们并没有创建T_Books表中的字段,并且也没有给字段指定类型,这时候EF Core将会默认把属性的名字作为表的列名,而且会根据属性的类型来推断出数据库中各个字段的数据类型。
第三步:创建一个继承自DbContext类的TestDbContext类(这个类名根据自己的习惯进行命名,但是一定要继承DbContext类),完成数据库的链接
TestDbContext类中的代码如下所示:
1 | public class TestDbContext:DbContext |
在TestDbContext这个类中,我们首先定义了Books属性,它的类型是DbSet<Book>泛型。**Books这个属性对应的就是数据库中的T_Books表,对Books的操作会反映到数据库的T_Books表中。**
当然,由于我们这里只有一个Book实体类,所以只创建了一个DbSet,如果项目中有多个实体类,对应的就需要创建多个DbSet.
在所对应的OnConfiguring方法中,对程序所要链接的数据库进行配置,指定了数据库连接字符串。
在OnModelCreating这个方法中,我们加载了当前程序集下实现了IEntityTypeConfiguration接口的类,也就是BookEntityConfig类(该类在当前项目所对应的程序集中),这样才能在数据库中创建T_Books这个数据表。
第四步:完成”迁移”操作
通过前3步,已经完成了主要的C#代码,下面我们要操作的就是创建对应的数据库与数据表。
在传统软件开发的流程中,数据库表的创建是由开发人员手工完成的,而在使用EF Core的时候,我们可以从实体类的定义中自动生成数据库表。这样开发人员可以专注于实体类模型的创建,而创建数据库表这样的事情就交给EF Core完成。这种先创建实体类再生成数据库表的开发模式叫作“模型驱动开发”,区别于先创建数据库表后创建实体类的“数据驱动开发”。EF Core这种根据实体类生成数据库表的操作也被叫作“迁移”(migration)。
为了能够完成迁移的操作,需要安装包Microsoft.EntityFrameworkCore.Tools
1 | Install-Package Microsoft.EntityFrameworkCore.Tools |
如果不安装以上包,在通执行Add-Migration等迁移命令的时候会提示错误信息“无法将Add-Migration项识别为cmdlet、函数、脚本文件或可运行程序的名称。”
下面我们就可以在“程序包管理器控制台”中执行Add-Migration进行迁移。
1 | Add-Migration InitialCreate |
在Add-Migration命令后面,我们一般都会带上一个有意义的参数,参数的名字可以根据自己的情况来确定。
为什么要带上参数呢?
由于项目比较复杂,实体类不能一次都创建完,或者 说后期又需要增加新的模块,这样就需要创建新的实体类,EF Core也会根据我们所创建的新的实体类生成对应的表。如果某个实体类不需要了, 或者某个实体类中的某个属性不需要了,EF Core也会进行“回滚”的操作,对应的会删除数据库中对应的表,或者是表中的某个字段。也就说,每次实体模型发生变化后,都需要进行迁移操作,为了能够区分每次迁移的操作,所以才会在Add-Migration命令后面添加上一个参数。这样后期需要回滚的时候,也可以根据这个参数名字回滚到对应的步骤。
在执行Add-Migration InitialCreate命令的时候,有可能会出现如下的错误:
Build failed
这时候,需要重新生成解决方法,把项目重新生成一下,看一下代码中是否有错误。
同时还要注意的一点就是不能将Program.cs中的默认代码删除,如果删除了,不会自动生成main函数,这时候也会出现错误。
执行完以上的命令后,在项目中会出现Migrations文件夹。
在该文件夹中先看一下20230311094632_InitialCreate.cs文件,其他文件后面再进行讲解
这个文件中包含用来创建数据库表的表名、列名、列数据类型、主键等的代码。
上面文件代码还没有执行,它们需要被执行后才会创建数据库,以及对应的表,因此我们接着在【程序包管理器控制台】中执行Update-database命令编译并且执行上面文件中的数据库迁移代码。
第五步:查看SQLServer数据库
我们可以看到Test数据库以及T_Books表已经创建好了。数据表T_Books的结构与实体类中的配置也是一样的。
同时我们可以看到还有一张表__EFMigrationsHistory,记录了迁移的历史记录。EF Core就是基于这张表得知当前执行了哪些迁移的操作,所以这张表不要删除及修改。该表中的ProductVersion字段表示EF Core的版本
4、EF Core基本使用2
了解了EF Core的基本使用以后,下面我们在创建一个实体类 Person,将其映射成对应的表。复习一下上一小节中所讲解的内容。
1 | public class Person |
以上就是所创建的实体类
下面创建PersonConfig.cs类,实现IEntityTypeConfiguration这个泛型接口。
1 | public class PersonConfig : IEntityTypeConfiguration<Person> |
在TestDbContext类这个类中,创建DbSet类型的属性。
1 | public class TestDbContext:DbContext |
下面完成迁移的操作,先执行Add-Migration这个命令,生成对应的迁移代码(在执行这个命令之前,最好重新生成项目,看一下代码有没有错误)
1 | Add-Migration AddPerson |
前面我们讲过Add-Migration命令后面一定要跟上一个参数。
执行完上面的Add-Migration命令后,查看Migrations目录下面会多出一个20230311131014_AddPerson.cs文件,由于创建T_Persons这张表。
最后执行Update-database命令编译上面文件中的代码,并且执行,从而完成数据库的迁移。
看一下Test数据库,发现在该数据库下面创建了T_Persons表,同时对应的字段与实体类中属性的配置一样。
同时在__EFMigrationsHistory表中也记录了这次迁移的历史记录。
以上的操作还是新增一个实体类,然后将其映射成表的操作。
如果,是对已经具有的某个实体类,修改其中的属性应该怎样操作呢?
例如,在Person这个实体类中,新增一个Birthday属性,应该怎样处理呢?
1 | public class Person |
现在,在Person类中新增了一个Birthday属性。
PersonConfig.cs这个文件中的代码不需要修改
TestDbContext.cs这个文件中的代码也不需要修改。
下面执行Add-Migration AddBirthday 生成迁移的代码
在Migrations文件夹下面有多了一个文件,叫做20230311133051_AddBirthday.cs,
打开这个文件,可以看到其中的代码,就是在表中增加一个Birthday字段。
最后执行Update-database命令,执行迁移的代码
查询数据库(这里最好将数据库刷新一下,这样才会更新),发现T_Persons表中,新增了一个Birthday列。
同时,在EFMigrationsHistory表中也记录了这一次的迁移操作。
5、EF Core基本使用3
现在虽然将实体模型映射成了对应的表,但是我们仔细观察一下表的结构就会发现还是有一定的问题的。
就拿T_Books这张表的结构,我们发现Title这个字段的类型是nvarchar(MAX),并且是允许为空。
为什么会出现这种情况呢?
因为,我们在创建实体类Book的时候,没有对其Title这个属性做过多的约束,所以才会出现这种情况。
Title这个属性的类型是string,没有指定长度,并且是可空类型,所以该属性对应的表中的Title这个字段的时候就变成了nvarch(Max),也就是c#中的string类型对应表中的nvarch类型,由于Title这个属性没有指定长度,对应的表中的Title字段就是Max,表示最大的长度,同时Title这个字段是可空类型,原因就是我们指定的Title这个属性就是可以为空的。
现在,我们要做的就是在将实体类中的属性映射成对应的表中字段的时候,做一下限制。
例如T_Books表中Title这个字段把它修改 为nvarch(50),不可为空。
把AuthorName这个字段修改为nvarch(50),不可为空。
这里需要修改BookEntityConfig.cs 类中的Configure方法,修改后的代码如下所示:
1 | public class BookEntityConfig : IEntityTypeConfiguration<Book> |
其中HasMaxLength(50)用来配置属性的最大长度为50,IsRequired用来配置属性的值为“不可为空”。
完成上面的修改后,再执行Add-Migration ModifyTitle_AuthorName
以上命令执行完毕以后,在在【程序包管理器控制台】中,会出现如下的警告信息:
1 | An operation was scaffolded that may result in the loss of data. Please review the migration for accuracy. |
由于我们把现有的Title的字段长度从MAX修改为了50,因此可能会造成数据库中旧数据的丢失,Add-Migration命令给出了“An operation was scaffolded that may result in the loss of data.”这个警告消息。
这时候,在Migrations这个文件夹中会增加一个20230311142012_ModifyTitle_AuthorName.cs文件,该文件中包含了修改T_Books表中的Title,AuthorName字段的长度。
在这里我们可以不用关心这个警告,在【程序包管理器控制台】中输入并执行Update-database命令.
当然,大家在以后的实体模型设计的时候,尽量确定好对应的属性类型和长度等。
可以看到,T_Books表的结构已经发生了改变(注意:为了能够看到最新的表的结构,最好刷新一下数据库)
从上面的操作可以看到,每次需要把对实体类的改动同步到数据库中的时候,就可以执行Add-Migration和Update-database命令。
至此,EF Core中实体类的定义以及根据实体类生成数据库修改操作的迁移已经完成。下面我们开始使用定义好的实体类对数据库数据进行操作。
6、EF Core数据的增删改查
6.1 数据的插入
TestDbContext类中的Books属性对应数据库中的T_Books表,Books属性是DbSet<Book>类型的。因此我们只要创建Book对象,并且给该对象中属性赋值,然后在添加到Books这个对应的DSet中,但是要注意的是Books这个DbSet中的数据只是修改了内存中的数据,最后还需要调用异步方法SaveChangesAsync把修改保存到数据库。其实DbContext中也有同步的保存方法SaveChanges,但是采用异步方法通常能提升系统的并发处理能力,因此我们推荐使用异步方法
代码如下所示:修改Program.cs
1 | using ConsoleApp; |
由于TestDbContext的父类DbContext实现了IDisposable接口,因此TestDbContext对象需要使用using代码块进行资源的释放。
以上就完成了数据的插入操作。
在数据插入的时候,我们只有调用了SaveChangesAsync这个方法才会将数据真正的插入到数据库。而该方法返回值是一个整数,表示影响的行数,也就是向数据库中插入数据的条数。
1 | var person = new Person(); |
同时,当数据插入成功以后,对应的person对象中Id属性的值是数据库中所插入记录的主键Id值。
6.2 数据查询
Books属性和数据库中的T_Books表对应,Books属性是DbSet<Book>类型的,而DbSet实现了IEnumerable<T>接口,因此我们可以使用LINQ操作对DbSet进行数据查询.
查询所有的书
1 | Console.WriteLine("打印所有的书"); |
查询价格大于50的书
1 | IEnumerable<Book> books= ctx.Books.Where(b => b.Price > 50); |
以上使用了where方法进行过滤,它返回的是IQueryable,但是它继承了IEnumerable,当然,我们为了省事,一般都是写成var
EF Core会将我们写的Linq最终转换成Sql语句。
查询编号为3的书
1 | var book = ctx.Books.Where(b=>b.Id==3).FirstOrDefault(); // var book = ctx.Books.FirstOrDefault(b => b.Id == 3); 以上过滤也可以省略Where方法 |
我们也可以使用OrderBy方法对数据进行排序
按照书的价格进行降序排序
1 | var books = ctx.Books.OrderByDescending(b => b.Price); |
我们也可以使用GroupBy方法对数据进行分组.
根据作者的名字进行分组,然后输出每一组中的数据条数及最高价格.(这里需要先向表中增加一条同名作者的记录,方便测试)
1 | var groups = ctx.Books.GroupBy(b => b.AuthorName).Select(g => new { AuthorName = g.Key, BooksCount = g.Count(), MaxPrice = g.Max(b => b.Price) }); |
6.3 修改和删除数据
修改数据:
如果要对数据进行修改,我们首先需要把要修改的数据查询出来,然后对查询出来的数据进行修改,再执行SaveChangesAsync保存修改即可.
1 | var book = ctx.Books.FirstOrDefault(b => b.Id == 5); |
同样,要对数据进行删除,我们要先把待删除的数据查询出来,然后调用DbSet或者DbContext的Remove方法把数据删除,再执行SaveChangesAsync方法保存结果到数
1 | var book = ctx.Books.FirstOrDefault(b => b.Id == 2); |
值得注意的是,无论是上面的修改数据的代码还是删除数据的代码,都是要先执行数据的查询操作,把数据查询出来,再执行修改或者删除操作。这样在EF Core的底层其实发生了先执行Select的SQL语句,然后执行Update或者Delete的SQL语句。
7、实体类配置
7.1 规则说明
通过前面的学习,我们知道作为ORM框架,EF Core要完成实体类与数据库表的映射,以及实体类的属性与数据库表的列映射
在BookEntityConfig.cs这个文件中,在其对应的Configure方法中,通过 builder.ToTable("T_Books");这行代码,实现了将类型DbSet<Book>类型的Books属性与T_Books表进行了映射。
但是如果我们不添加builder.ToTable("T_Books");这行代码,默认的表名就是Books,也就是与DbSet<Book>类型对应的Books属性同名。这其实就是EF Core的默认规则。
当然,在很多情况下使用默认的规则是完全可以的,如果默认的规则不满足需求的时候,我们可以显示的指定相应的规则。
下面我们看一下关于EF Core中主要的一些默认约定的规则。
第一:数据表的名称会与DbSet类型的属性同名。
第二:数据表中的字段的名字与实体类中属性名字一致,并且字段的类型采用的是和实体类中属性类型兼容的类型。比如在SQLServer中,nvarchar对应的string,bigint对应的是long类型。
第三:数据表中的字段是否允许为空,取决于对应的实体类属性的可空性。
例如,Person类中的Name属性,这里指定了属性是可空的,对应的表中的Name字段也是允许为空的。
1 | public string? Name { get; set; } |
第四:名字为Id的属性为主键,如果主键为short、int或者long类型,则主键默认采用自动增长类型的列。
7.2 Data Annotation
在前面的可成中,我们对实体类进行配置的时候,都是将相关的配置代码写到了一个实现了IEntityTypeConfiguration接口的文件中,这种配置方式我们一般叫做Fluent API``。当然,在``EF Core中还有另外的一种针对实体类进行配置的方式,就是可以使用.Net提供的Attribute对实体类以及对应的属性进行标注,通过这种标注的方式来完成对实体类的配置。例如,我们可以通过[Table("T_Books")],把实体类对应的表名配置为T_Books,
通过[Required],我们可以把属性对应的数据库表字段配置为“不可为空”;通过[MaxLength(20)],我们可以把属性对应的数据库表字段配置为“最大长度为20”,”[Key]”表示主键, 这种通过标注的方式来完成的配置,我们称作为Data Annotaion(数据注释)
在项目中创建创建Student.cs类,该类中定义的属性如下所示:
1 | namespace ConsoleApp |
在Student这个实体类中添加了[Table],并且给属性添加了[MaxLength],[Required]`.
这里需要注意的一点就是,既然这里我们采用了标注的这种方式来完成配置,就不需要再创建一个实现了IEntityTypeConfiguration泛型接口的类来完成配置了。
下面修改TestDbContext.cs类文件中的代码,
1 | public class TestDbContext:DbContext |
在上面的代码中,添加了Students这个DbSet类型的属性。表示T_Students这个数据表与当前的Students属性建立了映射的关系。
下面执行数据迁移的操作。
1 | Add-Migration AddStudent |
完成数据迁移的操作以后,刷新数据库Test,可以看到在该数据库中创建了T_Students表,同时表中的字段以及字段的类型按照相应的配置也已经创建好了。
通过对比,我们发现Data Annotation这种方式更加的简单,只需要在实体类以及对应的属性上添加Attribute就可以了,我们不再单独的写配置类了,但是Fluent API是微软官方推荐的使用方式
主要有两点原因:
第一:Fluent API这种方式体现了职责分明。实体类中只定义属性,不涉及到数据库配置相关的内容,针对数据库相关的配置都单独的放到配置类中,这样方便进行管理。
第二:Fluent API功能更强大,Fluent API几乎实现了Data Annotation所有的功能,而Data Annotation则不支持Fluent API的一些功能。
Data Annotation和Fluent API是可以一起使用的。如果同样的内容用这两种方式都配置了,那么Fluent API的优先级高于Data Annotation的优先级。比如一个实体类上既添加了[Table("TableFromAttribute")],又设置了ToTable("TableFromFluent"),那么EF Core认为配置的数据库表名是TableFromFluent。
关于实体类的配置在开发社区有两种方案:
第一:混合方案:优先使用Data Annotation,因为Data Annotation的使用更简单。在Data Annotation无法实现的地方,再使用Fluent API进行配置。但是个人不建议采用这种方式,容易造成混乱。
第二:单一方案:只使用Fluent API。
后面我们使用的配置方式也是Fluent API这种方式。
在下一小节中,我们再来看一下关于Fluent API中的其他的一些基本配置。
7.3 Fluent API基本配置
在这一小节中,我们只是看一下关于Fluent API的一些基本的配置,不在做演示。
1、排除属性
默认情况下,一个实体类的所有属性都会映射到数据库表中作为表的字段,如果想让EF Core忽略一个属性,就可以用Ignore配置。比如下面的代码表示把Person实体类中的Age属性排除:
1 | public class PersonConfig : IEntityTypeConfiguration<Person> |
2、字段名
默认情况下数据表中的字段名与实体类中的属性名是一样的,如果想不一样,可以通过HasColumnName方法来进行配置一个不同的字段名。
1 | public void Configure(EntityTypeBuilder<Person> builder) |
在上面的代码中,我们将Id修改成了person_id.
3、 字段类型
EF Core默认会根据实体类的属性类型、最大长度等确定字段的数据类型,我们可以使用HasColumnType为列指定数据类型。比如EF Core在SQL Server数据库中对于string类型的属性,默认生成nvarchar类型的字段,我们可以通过下面的代码把列的数据类型改为varchar:
1 | public void Configure(EntityTypeBuilder<Person> builder) |
4、主键
在EF Core中默认会将Id属性作为主键,当然我们也可以让其他的属性作为主键,这时候就需要使用HasKey方法来进行配置,如下所示所示:
1 | public void Configure(EntityTypeBuilder<Person> builder) |
在实际应用中还是建议将Id作为主键。
5、设置默认值
这里我们也可以设置属性的默认值,对应的映射到的字段中也会有默认值。
设置默认值需要使用到HasDefaultValue方法,如下所示:
1 | public void Configure(EntityTypeBuilder<Person> builder) |
在上面的代码中,将Age属性的默认值设置为18.
6、索引
EF Core中可以用HasIndex方法配置索引,如果下面代码所示
1 | public void Configure(EntityTypeBuilder<Person> builder) |
当然,也可以将多个属性设置为复合索引
1 | public void Configure(EntityTypeBuilder<Person> builder) |
构建复合索引就是给HasIndex方法传递一个匿名类对象,在该匿名类对象中指定构建复合索引所需要的多个属性即可。
在默认情况下,EF Core中定义的索引不是聚集索引,我们可以使用IsClustered方法把索引设置为聚集索引。
1 | public void Configure(EntityTypeBuilder<Person> builder) |
如果是唯一所索引,使用IsUnique方法
1 | builder.HasIndex(x => x.Name).IsUnique(); |
关于索引不太了解的同学,请看一下数据库相关的课程。
7、方法重载
在使用Fluent API的时候还有一点需要注意,Fluent API中的很多方法都有多个重载方法.
例如HasIndex,设置索引可以有如下两种方式
1 | builder.HasIndex(x => x.Name); |
同样地,用来获取实体类属性的Property方法也有多个重载方法,例如:把Id属性对应的数据表中的字段定义为person_id,有两种方式。
1 | builder.Property(b => b.Id).HasColumnName("person_id"); |
这里个人建议使用lambda表达式的写法,
因为这样可以利用C#的强类型检查机制,如果属性名字被写错了,编译器会报错。如果用Property("Number")这种写法,我们的拼写错误是没有那么容易被发现的。
以上这些特性根据自己的实际情况来使用。
更多关于Fluent API可以参考文档:
1 | https://learn.microsoft.com/zh-cn/ef/core/modeling/entity-properties?source=recommendations&tabs=data-annotations%2Cwithout-nrt |
8、数据库迁移原理
通过使用Add-Migration和Update-database两个命令,我们对于EF Core的数据库迁移有了基本的了解.
在这一小节中,我们来看一下迁移的一些原理。
我们知道Migrations文件夹下的内容都是数据库迁移生成的代码,这些代码记录了对数据库的修改操作,一般情况下我们无须手工修改这些代码,而且每次执行Add-Migration命令之后,在Migrations文件夹下面都会生成两个文件,一个文件的名字是数字_迁移名字.cs,另外一个文件的名字是”数字_迁移名字.Designer.cs“.而我们将每一次执行Add-Migration命令称作一次迁移。这些以数字开头的一组文件就对应了一次迁移,这些迁移开头的数字就是迁移的历史版本号,这些历史版本号是递增的,因此我们根据这些历史的版本号就知道数据库进行了哪些迁移。
当然,我们并不是修改了一个属性就进行迁移,而是根据实际情况,完成了某个功能或者是某个模块对应的实体类修改后,才会进行一次的迁移操作。
下面我们再来看一下迁移脚本文件中的代码。
先看一下20230311094632_InitialCreate.cs这个文件,在这个文件中有两个方法,分别是UP和Down方法。
我们看到20230311094632_InitialCreate.cs这个文件中UP方法中的代码就是调用了CreateTable方法,创建了T_Books这个表,并且定义了实体类中的属性与表中字段之间的对应关系。而Down方法中则调用了DropTable这个方法把T_Books表删除,相当于一个回滚的操作。
下面我们再来看一下20230311131014_AddPerson.cs这个文件,该 文件中的UP方法中创建了T_Persons这张表,Down方法删除了T_Persons这个表,还有一个文件是20230311133051_AddBirthday.cs(这个版本号比上一个文件大,表示最新的操作),在它的UP方法中向T_Persons表中添加了Birthday这个字段,而Down方法中从T_Person这张表中删除了Birthday这个字段。
下面我们再来看一下20230311094632_InitialCreate.Designer.cs这个Designer文件。
这个文件中使用了partial这个关键字定义了部分类,其实20230311094632_InitialCreate.cs这个文件中也是通过partial定义的部分类,这样共同构成了一个完整的InitialCreate类。
在20230311094632_InitialCreate.Designer.cs这个文件中,我们可以看到有如下代码:
1 | [] |
表示迁移脚本是有哪个DbContext来执行。
1 | [] |
表示DbContext要执行的迁移脚本的版本号。
在下面的BuildTargetModel方法中,完成的主要工作就是通过HasColumnType这个方法确定了实体类中属性最终所生成的与之对应的字段类型。例如:Title这个属性最终生成的字段的类型是nvarchar(max).
TestDbContextModelSnapshot.cs这个文件中定义了所有属性所对应的表中字段的类型,是否为空等信息。
注意:
如果解决方案中有多个项目,在执行Add-Migration等命令的时候,一定要确认在【程序包管理器控制台】中选中的是要迁移的项目。
9、其他数据库迁移命令
除了Add-migration、Update-database这两个常用命令之外,EF Core还提供了其他一些数据库迁移命令。这些命令被使用的机会相对来讲比较少,这里只介绍常用的功能。
(1) Update-database其他参数
在使用Update-database这个命令的时候,我们可以在后面添加参数。所添加的参数是迁移文件的版本号,这样就可以回滚到所写的版本号迁移脚本对应的状态。注意:这个命令只是把当前链接的数据库进行回滚,迁移的脚本文件不会删除。
1 | Update-database 20230311131014_AddPerson |
通过以上命令,我们可以看到混滚到了AddPerson这个状态,对应的Test数据库中的__EFMigrationsHistory中只保留了20230311094632_InitialCreate和20230311131014_AddPerson这两个状态。同时,我们可以看到在T_Persons表中已经没有了Birthday这个字段,因为添加Birthday这个字段是有20230311133051_AddBirthday.cs这个迁移脚本文件完成的,现在回滚到它之前的20230311131014_AddPerson这个状态,所以Birthday这个字段就被删除了,同时T_Students表也被删除了。
但是,我们查看Migrations文件夹的时候,发现所有的迁移脚本文件还是存在的。
如果这时候,我们又执行了Update-database这个命令,但是这时候我们没有给该命令添加任何的参数,它会执行所有的数据库迁移脚本文件,这样数据库中又创建了对应的表和字段。
(2) 删除脚本文件
如果某个迁移的脚步文件不需要了,可以将其删除。但是在删除的时候一定要注意,不要直接手动将Migrations文件夹下的脚步文件删除,这样有可能会破坏脚本文件之间的历史关系。
最好通过Remove-migration命令来进行删除。
使用该命令的时候,它后面不需要添加参数。
执行一次该命令就可以将最后一次生成的迁移脚本文件,如果想把所有的迁移脚本文件都删除,可以多次执行该命令。
大家可以自己演示。
(3)生成SQL脚本
当我们执行了Update-database这个命令以后会执行迁移脚本文件来修改数据库中的内容,例如新建表,创建字段或者是删除字段等操作。
但是,这种方式只是适合开发环境,也就是我们在开发项目的时候使用该命令。但是在生产环境中,是不允许是使用该命令的。也就是不能直接针对生产环境的数据库进行操作。因为很多公司要求对生产环境中的数据库进行操作需要进行审核,一般都是有数据库管理员审核一下对应的SQL脚本,发现没有问题了,才会进行操作。而Update-database这个命令是不满足这种需求的。而且,大部分公司的开发环境也是不能直接链接生产环境中的数据库的。
为了满足以上的需求,EF Core中提供了Script-Migration命令来根据迁移脚本文件生成SQL脚本,但是这个SQL脚本并没有执行,有数据库管理员审核通过了,才会在生产环境中执行
我们可以在【程序包管理控制】中直接输入Script-Migration命令,执行该命令后会生成一个完整的SQL脚本文件。
审核这个SQL脚本文件没有问题以后,可以直接拷贝到SQLServer中进行执行。
现在有一个问题:我们仅仅是在Person这个实体类中添加了Birthday属性
如果执行Script-Migration命令,我们可以看到所生成的SQL脚本中包含了CREATE TABLE [T_Persons]的操作,也就是创建Person这个实体类对应的T_Persons这张表,但是问题是,数据库中已经有T_Persons这张表了,在执行Create Table的操作不合适。
那么应该怎样进行处理呢?
可以输入如下命令
1 | Script-Migration AddPerson AddBirthday |
第一个参数表示的是当前版本(AddPerson是迁移脚本文件名,注意这里不用写历史编号)到最新版本AddBirthday的SQL脚本。
AddPerson这个版本对应的迁移脚本中只是创建了T_Persons这个表,并且创建了对应的Id,Name,Age字段
AddBirthday这个版本中创建了Birthday字段。
这时候生成的SQL脚本,如下所示:
1 | BEGIN TRANSACTION; |
通过上面的SQL脚本,我们可以看到修改了T_Person表,向该表中添加了Birthday这个字段,同时会向EFMigrationsHistory表中插入一条历史记录。
但是要注意的是,该SQL脚本并没有执行,可以拷贝到SQLServer中执行。
以上就是比较常用的数据库迁移命令。
10、反向工程
我们在使用EF Core的时候,推荐代码优先的使用方式,这种方式我们称作Code First,也就是先创建实体类,然后根据实体类生成数据库与表。
但是在实际的项目开发中,我们也会遇到数据库和表已经存在了的情况,例如公司中会有一些旧的项目,需要升级。而这些旧项目对应的数据库中已经有相应的表了,这时候我们就需要根据已经存在的数据表生成实体类,这种开发的方式称作DB First.
但是,大家在做新项目的时候,还是建议使用Code First这种开发方式
重新创建一个项目进行演示。
当然,在新创建的项目中也要安装EF Core所需要的包。
这里我们可以通过一种简单的方式安装EF Core的包,可以单击第一次创建的项目,从打开的文件中将如下的配置
1 | <ItemGroup> |
拷贝到新的项目中,当然这里需要单击新项目名称,在打开的文件中添加如上的配置。这样就可以在新项目中安装以上的包了。
下面,在【程序包管理器控制台】中执行如下的命令(注意:这里在【程序包管理器控制台】中一定要选择新创建的项目名称)
1 | Scaffold-DbContext 'server=.;database=Test;uid=sa;password=123456;TrustServerCertificate=true' |
执行完以上的命令以后,就可以看到在项目中创建了对应的实体类与DbContext.(TestContext.cs)
打开TestContext.cs文件可以看到在该文件中创建了对应的DbSet,在OnModelCreating方法中完成了表的创建以及字段的创建。这里没有帮我们创建一个实现了IEntityTypeConfiguration接口的文件。其实通过这一一点,我们也能够体会出,这种DB First开发方式不太友好的地方,就是OnModelCreating方法会变得比较臃肿。
同时这种开发方式生成的实体类也不太符合我们的需求。数据表的名称是T_实体类名称的复数形式,而反向工程操作以后生成的类型是TBook这样的类名,而不是我们希望的Book这样的类名。因此反向工程生成的代码还需要我们手动修改。
综上所述,反向工程只是适合老项目中已经有表了,现在需要根据表创建对应的实体类,当然还需要修改一下创建的实体类。
否则,无论是在老项目中添加新模块,还是进行新项目的开发,建议大家都使用Code First这种开发方式。
11、查看EF Core生成的SQL语句
通过前面的学习我们知道,使用了EF Core以后,一般情况下就不需要编写SQL语句了。在程序开发过程中,我们只需要写c#代码对实体类进行操作就可以了。这是因为EF Core会把我们写的C#代码转换成与之对应的SQL语句,然后在有ADO.NET Core交给数据库执行。
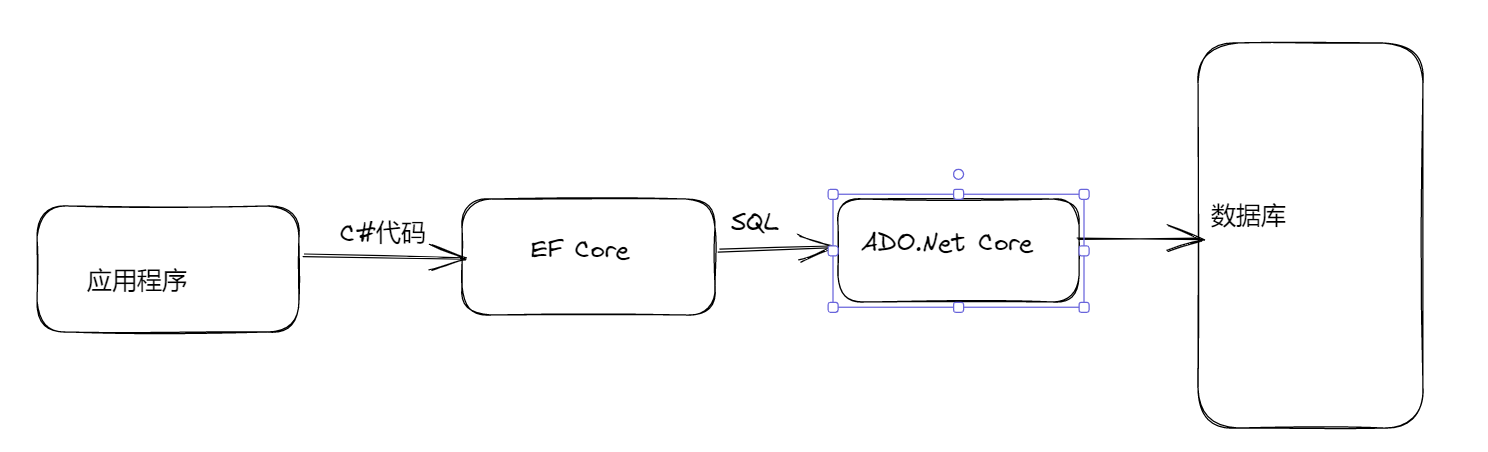
所以说EF Core并不是取代Ado.net 的,两者是一种合作的关系。
作为开发人员虽然使用了EF Core以后一般情况下不需要写SQL语句了,但是还是很有必要关注EF Core实现的SQL语句到底是怎样的。
比如说:当程序出性能问题以后,开发人员需要检查EF Core生成的SQL语句是否有性能缺陷,再比如说,当程序出现了Bug以后,我们需要检查一下EF Core生成的SQL语句是否和自己的预期是一致的。
下面我们就来看一下查看EF Core生成SQL语句的方式。
(1)使用简单日志查看SQL语句
自EF Core5.0 以后增加了一种”简单日志”的方式来查看程序所执行的SQL语句。
使用方式是在DbContext对应的OnConfiguring方法中调用optionsBuilder类的LogTo方法。给该方法传递一个参数为String的委托即可。
1 | protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) |
下面查看如下代码所生成的SQL语句
1 | var book = ctx.Books.Where(b => b.Id == 3).FirstOrDefault(); |
执行上面的代码,最终在控制台中查看到了最终所生成的SQL语句。
(2)使用SQL Server Profiler工具查看当前数据库所执行的SQL语句。
选择SQL Server数据库中的工具菜单中的SQL Servder Profiler
注意:该工具不仅可以查看当前我们自己程序所执行的sql语句,也可以看到其他开发人员链接我们数据库所执行的sql语句。
总结:EF Core就是把C#代码(例如以上所写的查询代码)转换成SQL语句的框架。
12、一对多关系配置
在进行项开发的时候,很少有一张表是单独存在的,大部分表之间都是有关系的。作为一个ORM框架,EF CORE不仅能够帮助开发人员简化单张表的处理,在处理表之间的关系上也非常强大。EF Core支持有一对多,多对多,一对一等。
下面我们先来看一下一对多关系的配置。
一对多是比较常见的表之间的关系。比如文章和评论的关系就是一对多的关系,也就是一篇文章对应多条评论。
下面我们就通过文章和评论两个实体类来讲解一对多关系的配置。
首先定义文章的实体类Article和评论的实体类Comment,如下代码所示:
Article实体类
1 | public class Article |
Comment实体类
1 | public class Comment |
在上面的实体类中,我们可以看到文章的实体类Article中定义了一个Comment类型的List属性,因为一篇文章可能有多条评论。
在评论的实体Comment中定义了一个Article类型的属性,因为一条评论只能属于一篇文章。
在EF Core中实体类之间关心的配置采用如下的模式:HasXXX().WithYYY(...)的形式。关于XXX,YYY有One和Many两个可选值。
假如我们在A这个实体类中配置builder.HasOne<B>(...).WithMany(...) 表示A和B是“一对多”的关系,也就是一个A实体类的对象对应一个B实体类对象,而一个B实体类的对象有多个A实体类的对象与之对应;
如果在A实体类中配置builder.HasOne<B>(…).WithOne(…)就表示A和B是“一对一”的关系,也就是一个A实体类的对象对应一个B实体类的对象,而一个B实体类的对象也有一个A实体类的对象与之对应.
如果在A实体类中配置builder.HasMany<B>(…).WithMany (…)就表示A和B是“多对多”的关系,也就是一个A实体类的对象对应多个B实体类的对象,而一个B实体类的对象也有多个A实体类的对象与之对应。
了解了配置关系以后,下面我们开始完成Article实体类与Comment实体类之间一对多关系的配置。
配置具体关系之前,在新创建的项目中先安装EF Core所需要的包
1 | <ItemGroup> |
下面创建ArticleConfig类实现IEntityTypeConfiguration<Article>泛型接口,代码如下所示:
1 | public class ArticleConfig : IEntityTypeConfiguration<Article> |
下面创建CommentConfig类实现IEntityTypeConfiguration<Comment>泛型接口。
1 | public class CommentConfig : IEntityTypeConfiguration<Comment> |
在上面的代码中,对于一对多的关系配置,主要通过如下代码完成
1 | builder.HasOne<Article>(c=>c.Article).WithMany(a=>a.Comments).IsRequired();// 简单理解:我有一篇文章,文章有多条评论 |
因为这个关系的配置写在了Comment实体类的配置中,所以这行代码的意思就是”一条评论对应一篇文章,一篇文章有多条评论”。
HasOne<Article>(c=>c.Article)中的Lambda表达式c=>c.Article表示Comment类的Article属性是指向Article实体类型的
WithMany(a=>a.Comments)表示一个Article对应多个Comment,并且在Article中可以通过Comments属性访问到相关的Comment对象。
下面创建DbContext对象。
1 | public class TestContext: DbContext |
下面进行数据库迁移的操作
1 | Add-Migration createInit |
注意:在[程序包管理器控制台]中,默认项目选择当前的项目
下面返回数据库中,查看生成的表。
其中T_Comments表的ArticleId列是一个指向T_Articles表Id列的外键。
下面,我们编写代码测试数据的插入。
1 | using 一对多关系; |
在上面的代码中我们可以可以看到,只要把创建的Comment类的对象添加到Article对象的Comments属性的List中,然后把Article对象添加到ctx.Articles中,就可以把相关联的Comment对象添加到数据库中,不需要显式为Comment对象的Article属性赋值(当前赋值也不会出错),也不需要显式地把新创建的Comment类型的对象添加到上下文中,因为我们的关系配置可以让EF Core自动完成这些工作。
13、关联数据的获取
EF Core的关系配置不仅能帮助我们简化数据的插入,也可以简化关联数据的获取。如下代码,把编号为1的文章以及对应的评论查询出来。
1 | using (TestContext ctx = new TestContext()) |
这里我们使用了异步的方法FirstOrDefaultAsync获取编号是1的文章,然后再获取该文章对应的评论。
但是,执行程序的时候,发现文章的标题展示出来了,但是该文章对应的评论没有展示出来。
原因是什么呢?
下面查看一下以上代码所生成的SQL语句。
1 | SELECT TOP(1) [t].[Id], [t].[Content], [t].[Title] |
通过所生成的SQL语句,可以看到只是查询了T_Articles表,并没有查询关联的T_Comments表。也就是说在生成的SQL语句中没有使用join语句关联查询T_Comments表,因此我们无法获取Comments属性中的数据。
要想关联T_Comments表进行查询,需要使用到Include方法,如下代码所示:
1 | using Microsoft.EntityFrameworkCore; // 引入命名空间 |
注意:Include方法是定义在Microsoft.EntityFrameworkCore;命名空间中的扩展方法,所以在使用这个方法之前,需要再代码中添加该命名空间的引用。
运行程序,可以看到编号为1的文章以及该文章具有的评论都查询出来了。
生成的SQL语句,如下所示:
1 | SELECT [t0].[Id], [t0].[Content], [t0].[Title], [t1].[Id], [t1].[ArticleId], [t1].[Message] |
通过生成的SQL语句我们可以看到,C#代码被翻译成了Left Join语句对T_Articles和T_Comments表进行了关联查询。
问题:查询编号为3的评论以及该评论对应的文章信息。
1 | Comment? cmt = await ctx.Comments.FirstOrDefaultAsync(c => c.Id == 3); |
在上面的代码中,我们先查询了编号为3的评论内容。这里是可以查询出来的。
下面查询该评论对应的文章。
1 | Comment? cmt = await ctx.Comments.FirstOrDefaultAsync(c => c.Id == 3); |
这里也是需要Include方法,如下所示:
1 | // 这里使用了Include方法 |
看一下生成的SQL语句
1 | SELECT TOP(1) [t].[Id], [t].[ArticleId], [t].[Message], [t0].[Id], [t0].[Content], [t0].[Title] |
这里生成了inner join关联查询。
14、额外设置外键字段
这里我们又一个需求:
查询编号为3的评论对应的文章编号,注意这里我们只需要文章编号。
这里,我们可以采用上一小节的做法,代码如下所示:
1 | Comment? cmt = await ctx.Comments.Include(c => c.Article).FirstOrDefaultAsync(c => c.Id == 3); |
可以看到到以上的代码与我们上一小节中写的代码是一样的,只不过这里仅仅打印的是文章的编号。
虽然实现了我们的要求,但是这种实现方式是有问题的,我们来看一下上面代码所生成的SQL语句。
1 | SELECT TOP(1) [t].[Id], [t].[ArticleId], [t].[Message], [t0].[Id], [t0].[Content], [t0].[Title] |
我们看到在上面的sql语句中,进行了链接查询,也就是说,这里还查询了T_Articles表,但问题是,在T_Comments这张表中,有一个ArticleId,这是与T_Articles表进行关联的外键。我们在创建Comment这个实体类的时候,创建了Article属性,它的类型是Article,在映射成数据的表的时候,根据Article这个属性会在T_Comments表中创建一个ArticleId外键,与对应的T_Articles表进行关联。
了解这些内容以后,我们就可以想到,这里我们要获取编号为3的这条评论对应的文章编号,没有必要去关联T_Articles表,直接就可以从T_Comments表中查询出ArticleId,问题是怎样实现呢?
如果,我们有单独获取外键列值的需求,我们可以在实体类中显式声明一个外键属性。
比如,我们在Comment类增加一个long类型的ArticleId属性,然后在关系配置中通过HasForeignKey(c=>c.ArticleId)指定这个属性为外键就可以了。
Comment类中的代码如下所示:
1 | public class Comment |
修改CommentConfig.cs类中的代码,如下所示:
1 | public void Configure(EntityTypeBuilder<Comment> builder) |
由于,数据表的结构没有修改过,所以这里不需要迁移数据表的操作(因为在数据表T_Comments中,外键字段就是ArticleId)。
直接进行查询就可以了,下面修改前面所写的代码,如下所示,
1 | Comment? cmt = await ctx.Comments.FirstOrDefaultAsync(c => c.Id == 3); |
在上面的代码中不需要使用Include方法来关联Article,直接查询Comments,然后打印ArticleId
然后再来看一下所生成的SQL语句。
1 | SELECT TOP(1) [t].[Id], [t].[ArticleId], [t].[Message] |
通过以上生成的SQL语句,我们可以看到这里没有在关联,T_Articles表。只是查询了T_Comments表,这样查询的效率得到了提升。
当然,采用这种方式我们需要额外再维护一个外键属性,增加了开发复杂度,因此一般情况下我们不需要这样声明。除非以前的写法确实影响到了性能。
这里我们还可以对以上查询做进一步的优化。这里我们只需要查询ArticleId,但是通过上面的sql语句,我们可以看到,这里将Id,Message字段也查询出来了,但是这些并不是我们需要的,所以可以对以上的代码做进一步的优化。
1 | // 注意:这里使用了Select投影,这里指定了匿名类,所以变量cmt的类型只能是用var来修饰 |
在上面的代码中,通过Select方法完成了投影的操作,也就是只查询Id,和ArticleId,这里为什么还有指定Id呢?因为在FirstOrDefaultAsync方法中进行过滤的时候使用到了Id.通过这里使用了Select投影,这里指定了匿名类,所以变量cmt的类型只能是用var来修饰 .
执行以上代码,生成的SQL语句如下所示:
1 | SELECT TOP(1) [t].[Id], [t].[ArticleId] AS [AId] |
通过以上SQL语句,我们可以看到这里只查询了Id,``ArticleId.
通过以上两个知识点的讲解,我们可以总结出:
在使用EF Core的过程中如果出现了性能问题,可以进行优化,
由于EF Core是有微软官方推出的,所以EF Core所生成的大部分查询的SQL语句的性能都比较高,有少部分SQL语句性能可能不尽如意,但是也影响不大,除非一些特殊的SQL语句可能影响性能了,这时候才进行优化,看一下生成的SQL语句,如果不满足性能需求,这时候只能自己写SQL语句。
15、单向导航属性
在前面我们所创建的Article类中声明了Comments属性指向了Comment类,在Comment类中声明了Article属性指向了Article类。
这样我们不仅可以通过Comment类的Article属性获取评论对应的文章信息,也可以通过Article类中的Comments属性获取文章对应的所有评论信息。这样的关心叫做双向导航。
所以说:双向导航让我们可以通过任何一方的对象获取到对方的信息。
但是,在有些情况下我们不方便声明双向导航。
如下图所示:
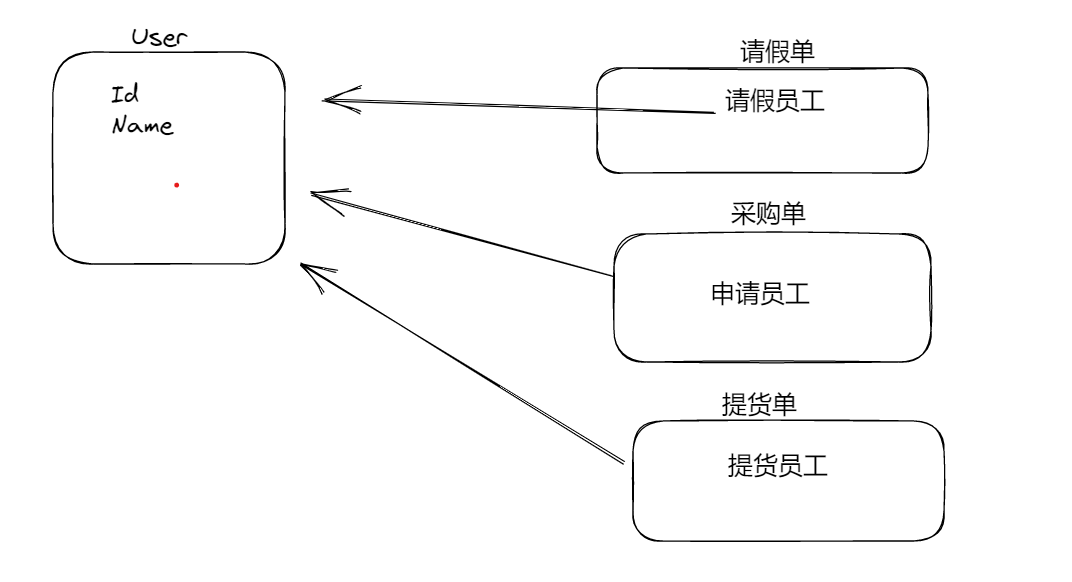
通过上图,我们可以看到,这里有很多的的实体类都与User实体类相关,如果是双向导航,我们还需要在User实体类中创建对应的多个属性。这样会导致User这个实体非常的臃肿。所以这里我们没有必要在User实体类中在创建导航属性了,只是在其他的实体类中创建导航属性,指向User这个实体类就可以了。
,例如请假单这个实体类中,不仅有请假员工这个属性指向了User实体了,同时还有审批人这个属性指向User这个实体类,这样的话,在User实体类中就没有必要在创建属性指向请假单实体类了,像这种情况就是单向导航。
这种单向导航属性的配置比较简单,只要在WithMany方法中不指定属性就可以了。
下面就以用户与请假单两个实体类举例。
这里我们重新创建项目,同时,拷贝EF Core需要的包。
创建User实体类
1 | public class User |
这里,我们可以看到在User这个实体类中没有创建指向请假单实体类的属性。
下面我们再来创建请假单实体类Leave,代码如下所示:
1 | public class Leave |
在Leave类中有Requester,Approver两个User 类型的属性,它们都是单向导航属性。
下面创建TestDbContext.cs 类。
1 | public class TestDbContext:DbContext |
下面创建User类的配置类UserConfig.cs
1 | public class UserConfig : IEntityTypeConfiguration<User> |
下面我们在创建Leave类的配置LeaveConfig.cs,代码如下所示:
1 | public void Configure(EntityTypeBuilder<Leave> builder) |
可以看到,Requester、Approver这两个属性都是单向导航属性,因为WithMany方法中没有传递参数,当然也没有合适的参数给WithMany方法,毕竟User类中没有指向Leave类的属性。
下面进行数据迁移
1 | Add-Migration Init |
注意:在【程序包管理器控制台】中选择当前新创建的项目,在执行以上数据库的迁移命令。
下面进行数据的插入
1 | using (TestDbContext ctx =new TestDbContext()) |
在上面的代码中,我们没有给leave.Approver属性赋值,因为以上的操作表示的是张三这个用户提交请假信息,还没有进行审批。
下面看一下数据查询的操作
例如:查询一下“张三”这个用户所有的请假单。
代码如下所示:
1 | using (TestDbContext ctx =new TestDbContext()) |
通过以上的代码,我们可以看到User实体类中没有指向Leave实体类的属性,如果要实现获取一个用户的所有请假单,我们可以直接通过TestDbContext对象去到Leaves这个DbSet中去查询。
如果,这里我们想查询一下编号为1的请假单对应的用户应该怎样查询?
1 | using (TestDbContext ctx =new TestDbContext()) |
这里我们需要通过Include关联上User进行查询。
在实际项目开发中,对于主从结构的“一对多”表关系(文章表与评论表),我们一般是声明双向导航属性;对于其他的“一对多”表关系,我们则需要根据情况决定是使用单向导航属性还是使用双向导航属性,比如被很多表都引用的基础表,一般都是声明单向导航属性。
16、关系配置在哪个实体类中
在前面的案例中,我们讲过Article和Comment之间的关系是一对多的关系,也就是一个Article对应多个Comment;当然,我们也可以说Comment和Article之间的关系是多对一,也就是多个Comment对应一个Article.站在不同的角度,就有不同的说法,但是本质上它们指的是同一个东西。
因为,两张表之间的关系是可以配置在任何一端,比如前面我们所讲的Article和Comment类,我们就可以把它们的关系配置进行交换。
下面就具体的来演示一下。(重新创建一个项目)
在新创建的项目中,添加EF Core所需要的包。
在新创建的项目中,创建Comment类,代码如下所示:
1 | namespace 关系配置在哪个实体类中 |
Article.cs类中的代码如下所示:
1 | namespace 关系配置在哪个实体类中 |
CommentConfig.cs类中的代码,如下所示:
1 | public class CommentConfig : IEntityTypeConfiguration<Comment> |
ArticleConfig.cs类中的代码如下所示:
1 | public void Configure(EntityTypeBuilder<Article> builder) |
可以看到,我们把关系的配置从CommentConfig类中移动到了ArticleConfig类中。当然,由于配置的位置变了,我们把CommentConfig类中的HasOne<Article>(c=>c.Article).WithMany(a=>a.Comments)改成了ArticleConfig类中的HasMany<Comment>(a=>a.Comments).WithOne(c=>c.Article)。
创建TestContext.cs类,代码如下所示:
1 | public class TestContext:DbContext |
数据库迁移(注意:在【程序包管理器控制台】中,选择当前新创建的项目)
1 | Add-Migration Init |
执行数据库迁移后,重新执行代码,查看TestDB数据库,我们会发现数据库结构和之前的没有任何区别,也就是说这两种配置方式的效果是一样的。
当然,对于单向导航属性,我们只能把关系配置到一方,也就说针对单向导航属性,还是使用HasOne(...).WithMany(...)的方式。
因此,考虑到有单向导航属性的可能,我们一般都用HasOne(…).WithMany(…)这样的方式进行配置,而不是像本小节这样“反其道而行之”。
18、一对一关系配置
实体类之间还可以有一对一关系,比如”采购申请”和”采购订单”,就是一对一关系。
在电商网站中,“订单”和“快递信息”这两个实体类之间也是一对一的关系:一个订单对应一个快递信息,一个快递信息对应一个订单。
下面我们来看一下一对一关系的配置。
首先,我们声明一个订单的实体类Order(这里我们简化了该实体类中的属性,实际中该实体类中的属性比较复杂)。
1 | public class Order |
下面我们再创建一个快递信息的实体类Delivery.cs ,代码如下所示:
1 | public class Delivery |
通过声明的两个属性,我们可以看到Order和Delivery两个类中分别声明了一个指向对象的属性,这样就构成了一对一的关系中。
在一对多的关系中,我们需要在“多”端有一个指向“一”端的列,因此除非我们需要显式地声明一个外键属性,否则EF Core会自动在多端的表中生成一个指向一端的外键列,不需要我们显式地声明外键属性。但是对于一对一关系,由于双方是“平等”的关系,外键列可以建在任意一方,因此我们必须显式地在其中一个实体类中声明一个外键属性。就像上面的实体类定义中,Delivery类中声明了一个外键属性OrderId,当然我们也可以改成在Order类中声明一个外键属性DeliveryId,效果是一样的。
下面对两个实体类进行配置。
OrderConfig.cs文件中的代码如下所示:
1 | public class OrderConfig : IEntityTypeConfiguration<Order> |
和一对多关系类似,在一对一关系中,把关系放到哪一方的实体类的配置中都可以。这里把关系的配置放到了Order类的配置中。这里的配置同样遵守HasXXX(…).WithYYY(…)的模式,由于双方都是一端,因此使用HasOne(…).WithOne(…)进行配置。由于在一对一关系中,必须显式地指定外键配置在哪个实体类中,因此我们通过HasForeignKey方法声明外键对应的属性。
下面创建DeliveryConfig.cs这个配置类
1 | public class DeliveryConfig : IEntityTypeConfiguration<Delivery> |
下面创建TestDbContext.cs,代码如下所示:
1 | public class TestContext:DbContext |
下面进行数据的迁移操作(看一下所生成的数据表的结构)
1 | Add-Migration Init |
下面进行数据的插入测试
1 | using (TestContext ctx =new TestContext()) |
当然,指定如下的关系也是可以进行插入的。
1 | using (TestContext ctx =new TestContext()) |
当然,也可以直接采用如下的写法:
1 | using (TestContext ctx =new TestContext()) |
在上面的代码中,我们将order与delivery都添加到对应的DbSet中,这种写法也可以。
这里就根据个人的习惯进行选择就可以了。
下面进行数据的查询
1 | var result = await ctx.Orders.Where(o => o.Id == 1).Include(o => o.Delivery).FirstOrDefaultAsync(); |
查询编号为1的订单的商品名称以及对应的订单号。
19、多对多
多对多指的是A实体类的一个对象可以被多个B实体类的对象引用,B实体类的一个对象也可以被多个A实体类的对象引用。比如在学校里,一个老师对应多个学生,一个学生也有多个老师,因此老师和学生之间的关系就是多对多。下面我们就使用“学生-老师”这个例子实现多对多关系。
新创建一个项目来实现多对多的配置
注意:将EF Core所需要的包拷贝过来。
下面我们先声明学生类Student和老师类Teacher.
Student类
1 | public class Student |
Teacher类
1 | public class Teacher |
可以看到,学生类Student中有一个List类型的Teachers代表这个学生的所有老师,同样地,老师类Teacher中也有一个List类型的Students代表这个老师的所有学生。接下来,我们开始对学生和老师实体类进行配置
下面,我们开始对学生和老师实体类进行配置。
如下代码所示:
TeacherConfig.cs文件中的代码如下所示:
1 | public class TeacherConfig : IEntityTypeConfiguration<Teacher> |
StudentConfig.cs文件中的代码如下所示:
1 | public class StudentConfig : IEntityTypeConfiguration<Student> |
同样地,多对多的关系配置可以放到任何一方的配置类中,这里把关系配置代码放到了Student类的配置中。这里同样采用的是HasXXX(…).WithYYY(…)的模式,由于是多对多,关系的两端都是“多”,因此关系配置使用的是HasMany(…).WithMany(…)。
一对多和一对一都只要在表中增加外键列即可,但是在多对多关系中,我们必须引入一张额外的数据库表保存两张表之间的对应关系。在EF Core中,使用UsingEntity(j=>j.ToTable ("T_Students_Teachers"))的方式配置中间表(当然,这行代码也可以不用加,但是生成的中间表命名不符合咱们的规范,所以如果想给中间表起一个符合咱们自己要求的名字建议加上这行代码)。
TestContext.cs文件中的配置代码如下所示:
1 | public class TestContext:DbContext |
下面进行迁移,注意选择当前新项目。
1 | Add-Migration Init |
查看数据库,可以看到数据库有一张额外的关系表T_Students_Teachers,这张表中有指向T_Students表的外键列StudentsId,也有指向T_Teachers表的外键列TeachersId。T_Students_Teachers表中保存了T_Students表和T_Teachers表中数据之间的对应关系,而我们不需要为这张关系表声明实体类。
下面进行数据的插入
1 | Student s1 = new Student {Name = "张三"}; |
在上面的代码中,我们是通过AddRange方法把多个对象批量的添加到了DbContext中。需要注意的是,AddRange方法只是通过循环调用Add方法把多个实体添加到DbContext中,是对Add方法的简化调用,在使用SaveChangesAsync的时候,这些数据任然是逐条的插入到数据库中的。
执行完以上的代码以后,查看数据库中的3张表。
下面进行查询的操作
(1)查询所有老师的信息,同时将每个老师所教学生信息也查询出来。
1 | using (TestContext ctx = new TestContext()) |
(2): 查询王老师所有学生(这里根据老师的编号来进行查询)
1 | var t =await ctx.Teachers.Include(s=>s.Students).Where(c => c.Id == 2).FirstOrDefaultAsync(); |
20、基于关系的复杂查询
在这一小节中,我们继续看一些关于基于关系的查询操作。
(1)查询一下评论中含有好字的文章。
1 | var articles = ctx.Articles.Where(a => a.Comments.Any(c=>c.Message.Contains("好"))); |
注意:这里没有使用include,因为在where中指定了Comments来进行查询。
在Where这个方法中,使用Any方法判断是否存在至少一条评论中包含好的文章。这里使用Any的目的是:如果一篇文章的评论中有多条评论都包含了好字,最终查询出的文章标题只有一个,相当于去重了。(这里可以修改表中的记录进行操作)。
下面我们看一下,上面查询所生成的SQL语句,如下所示:
1 | SELECT [t].[Id], [t].[Content], [t].[Title] |
通过上面的SQL语句,可以看到,我们所写的C#代码被EF Core翻译成了Exists加子查询的SQL语句。根据数据库的不同以及数据的特点,上面生成的SQL语句也许并不是性能最优的写法。所以将上面的查询修改成如下的形式:
1 | var articles = ctx.Comments.Where(c => c.Message!.Contains("好")).Select(c=>c.Article).Distinct(); |
上面的代码中使用Where方法获取所有包含好的评论,然后使用select方法获取评论对应的文章,并且使用Distinct()方法进行了去重的操作。
可以看到所生成的sql语句,同样的效果的代码被翻译成了使用Join查询的数据筛选。根据具体情况的不同,这种做法也许性能更好。
当然,对性能问题必须具体问题具体分析。
21、IEnumerable与IQueryable
我们知道,可以使用Linq中的Where等方法可以对普通集合进行处理,比如下面的C#代码可以把int数组中大于5的数字查询出来。
1 | int[] nums = { 1, 5, 6, 10, 35, 23 }; |
这里,我们可以看一下Where方法的具体定义,关于该方法的定义,我们前面也看过,如下所示:
1 | public static IEnumerable<TSource> Where<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate); |
Where方法是IEnumerable的扩展方法,同时返回的类型也是IEnumerable这个泛型接口。
下面我们再来看一下在EF Core中在DbSet类型上调用Where方法进行的数据筛选
1 | var articles = ctx.Comments.Where(c => c.Message!.Contains("好")).Select(c=>c.Article).Distinct(); |
这时候Where方法的定义如下所示:
1 | public static IQueryable<TSource> Where<TSource>(this IQueryable<TSource> source, Expression<Func<TSource, bool>> predicate); |
这时候Where方法是IQueryable的扩展方法,同时返回的也是IQueryable的泛型接口。
IQueryable其实就是一个继承了IEnumerable接口的接口。
1 | public interface IQueryable<out T> : IEnumerable<T>, IEnumerable, IQueryable |
这就比较奇怪了,IQueryable接口就是继承自IEnumerable接口的,IQueryable中的Where方法除了参数和返回值的类型是IQuerable,其他用法和IEnumerable中的Where方法没有什么不同。那微软为什么还要推出一个IQueryable接口以及一个新的Where方法呢?
对于普通的集合,Where方法会在内存中对每条数据进行过滤,而EF Core如果也把全部数据都在内存中进行过滤的话,我们就需要把数据表中的所有数据都加载到内存中,然后在通过条件逐条进行过滤,如果数据表中的数据量非常大,就会有性能问题。
因此,EF Core中的Where必须实现一套把 Where 条件转换为SQL语句的机制,让数据的筛选是在数据库服务器上执行。这样性能就会得到提升。
KilgourNote:Iqueryable是将Linq语句中的筛选条件直接在服务器上进行筛选然后传给用户。而IEnumerable则是将整张表都拿到用户手上置于内存里再在用户内存里进行筛选。
所以说,微软针对EF Core的查询又创造了IQueryable类型,并且在IQueryable中定义了和IEnumerable中类似的Where等方法。
因此,在使用EF Core的时候,我们要尽量调用IQueryable中的方法。而不是直接调用IEnumerable中的方法。
下面,我们再来看一个例子体会一下。
IQueryable数据查询(查询评论中包含好字的评论)
1 | var messages = ctx.Comments.Where(c => c.Message!.Contains("好")); |
生成的SQL语句如下所示:
1 | SELECT [t].[Id], [t].[ArticleId], [t].[Message] |
下面把上面的查询代码稍微修改一下,修改成IEnumerable的形式,如下所示:
1 | IEnumerable<Comment> comments = ctx.Comments; |
我们知道ctx.Comments的类型是DbSet类型.而DbSet类型也实现了IEnumberable类型。所以这里我们就强制性的将comments这个变量的类型定义成了IEnumerable<Comment>类型。
这样下面我们通过comments.Where进行过滤的时候,Where这个方法就是IEnumerable泛型接口类型的方法。
上面代码生成的SQL语句,如下所示:
1 | SELECT [t].[Id], [t].[ArticleId], [t].[Message] |
很明显,这里是将T_Comments表中所有的数据都加载到应用程序内存中,然后在内存中进行数据的过滤。
22、IQueryable延迟执行
在这一个小节中,我们看一下IQueryable另外的一个特性就是延迟执行的能力。
如下代码:
1 | var messages = ctx.Comments.Where(c => c.Message!.Contains("好")); |
以上代码是查询评论中包含好的评论。
但是,我们通过查看SQL Server Profile发现并没有生成对应的SQL语句,而我们明明是执行了Where方法进行数据过滤的查询。
下面,我们再把代码修改一下,如下所示:
1 | var messages = ctx.Comments.Where(c => c.Message!.Contains("好")); |
在上面的代码中,我们添加了一个foreach遍历
这时候,执行上面的程序,在控制台中打印了结果,并且在SQL Server Profile中也看到了对应的SQL语句。
也就是说,当执行foreach循环来获取数据的时候,才会生成sql语句交给数据库服务器执行。
这就说明了IQueryable代表了”可以把查询放到数据库服务中执行”,但是它没有立即执行,只是“可以被执行”而已。
这一点,我们可以从IQueryable它的英文含义中看出来,IQueryable的意思是”可查询的”,可以查询,但是没有执行查询,也就是说查询执行被延迟了。
那么问题是IQueryable是什么时候才会执行查询呢?
一个原则是:调用立即执行方法的时候会立即执行查询,除了遍历IQueryable操作之外,还有ToArray,ToList,Min,Max,Count等立即执行方法。
而GroupBy,OrderBy,Include,Skip,Take等方法是“非立即执行方法”,调用这些方法,不会执行查询。
判断一个方法是否是立即执行方法的简单方式是:一个方法的返回值类型如果是IQueryable类型,这个方法一般就是非立即执行方法,否则这个方法就是立即执行方法。
1 | ctx.Comments.Where(c => c.Message!.Contains("好")).Count() |
以上方法返回的是一个整型,表示的就是一个立即执行的方法,立即执行,返回满足条件的数据条数。
EF Core为什么要实现“IQueryable延迟执行”这样复杂的机制呢?因为我们可以先使用IQueryable拼接出复杂的查询条件,然后再去执行查询。
如下伪代码所示:
1 | void QueryBooks(string searchWords, bool searchAll, bool orderByPrice, double upperPrice) |
比如,下面的代码中定义了一个方法,这个方法用来根据给定的关键字searchWords查询匹配的书;如果searchAll参数是true,则书名或者作者名中含有给定的searchWords的都匹配,否则只匹配书名;如果orderByPrice参数为true,则把查询结果按照价格升序排序,否则就自然排序;upperPrice参数代表价格上限
上面的代码,只有执行了foreach的时候才会执行查询。
根据上面的伪代码,我们可以看到,我们传递不同的参数会拼接成不同的IQueryable,因此最后执行查询的时候生成的SQL语句也是不同的。
如果不使用EF Core而使用SQL语句实现根据不同参数执行不同SQL的逻辑,我们需要手动拼接SQL语句,这个过程是比较麻烦的,而EF Core把“动态拼接生成查询逻辑”变得非常简单。
总结:IQueryable表示对一个数据库中的数据进行查询的时候,是一个延迟查询。我们可以调用非立即执行方法向IQueryable中添加查询逻辑,实现根据不同参数拼接不同的IQueryable,当执行立即执行方法的时候才会真正生成SQL语句执行查询。
23、IQueryable复用性
由于IQueryable是一个待查询的逻辑,因此它是可以被重复使用的。
如下代码所示:(一对多项目中演示)
1 | IQueryable<Comment>comments = ctx.Comments.Where(c => c.Id >=1); |
在上面的查询中,我们首先创建了一个编号大于1的评论的IQueryable对象,然后再调用Count方法执行了IQueryable对象获取满足条件的数据条数,最后对于comments变量调用Where方法进一步过滤获取评论内容中包含好字的评论内容。
看一下所生成的SQL语句,如下所示:
1 | SELECT COUNT(*) |
通过以上的SQL语句,我们可以看到,执行Count进行统计的时候包含了Id >1条件,下面执行评论内容中是否包含好字过滤的时候,也包含了Id >1过滤的条件。
这就是说,后面的操作都包含了最开始的IQueryable指定的过滤条件,从而达到了复用IQueryable的目的。
IQueryable让我们可以复用之前生成的查询逻辑
24、分页查询
如果数据表中的数据非常多,在把查询结果展现到页面上进行展示的时候,我们通常要对查询结果进行分页展示。
例如:每页显示10条数据,然后用户单击不同的页码的时候,展示不同的数据,第一页展示1-10的数据,当单击第2页的时候,展示11-20的数据。
在学习Linq的时候,我们知道可以使用Skip(n)方法实现跳过n条数据,可以使用Take(n)实现获取最多n条数据,这两个方法配合起来就可以实现分页获取数据。比如Skip(3).Take(8)就是获取从第3条开始的最多8条数据。
在EF Core中同样也支持这两个方法。
下面对Student表中的数据进行分页展示。(多对多项目中进行演示,并且向数据表中添加一些测试数据)
要求: 对姓名中不包含张姓的学生进行分页展示。
1 | static void ShowPage(int pageIndex,int pageSize) |
ShowPage方法的pageIndex参数代表页码,pageSize参数代表页大小。在ShowPage方法中,我们首先把查询规则students创建出来,然后使用LongCount方法获取满足条件的数据的总条数。使用count×1.0÷pageSize可以计算出数据总页数,考虑到有可能最后一页不满,因此我们用Ceiling方法获得整数类型的总页数。由于pageIndex的序号是从1开始的,因此我们要使用Skip方法跳过(pageIndex−1)×pageSize条数据,再获取最多pageSize条数据就可以获取正确的分页数据了。
以上也是使用了IQueryable的复用性的特点。
25、IQueryable底层运行机制*
我们知道,在ADO.Net中有DataReader和DataTable两种读取数据库查询结果的方式。EF Core底层也是通过ADO.NET来操作数据库。
如果查询的数据比较多,DataTable会把所有数据一次性的从数据库服务器加载到客户端程序的内存中,而DataReader则会分批次从数据库服务器读取数据,并不是一次性的把数据加载到客户端程序的内存中,DataReader的优点是客户端程序内存占用小,缺点是如果遍历读取数据并且进行处理的过程比较缓慢的话,会导致程序占用数据库链接的时间较长,从而降低数据库服务器的并发链接的能力。
DataTable的优点是数据被快速的加载到客户端的内存中,因此不会较长时间地占用数据库链接,缺点是如果数据量比较大的话,客户端的内存会占用比较大。
IQueryable遍历读取数据的时候,用的是类似DataReader的方式还是类似DataTable的方式呢?
IQueryable内部的遍历是在调用DataReader进行数据读取的,因此,在遍历IQueryable的过程中,它需要一直占用一个数据库的链接。如果想一次性的把数据表中的数据读取到客户端程序的内存中,可以使用IQueryable的ToArray,ToArrayAsync,ToList、ToListAsync等方法。如下面的代码所示:
1 | var books = await ctx.Books.Take(50000).ToListAsync(); |
在上面的代码中,就是读取前5万条记录,然后使用ToListAsync方法把读取到的数据一次性的加载到内存中,然后再遍历输出数据。
在遍历数据的过程中,如果我们关闭SQL Server服务器或者断开服务器的网络,程序是可以正常运行的,这说明ToListAsync方法把查询结果加载到客户端内存中了。
除非遍历IQueryable并且进行数据处理的过程很耗时,否则一般不需要一次性把查询结果读取到内存中。但是在以下场景下,一次性把查询结果读取到内存中就有必要了。
第一:方法需要返回查询结果
如果方法需要返回查询结果,并且在方法中销毁了DbContext对象,方法是不能返回IQueryable的。如下代码所示(多对多项目中演示):
1 | static IQueryable<Student> QueryStudents() |
运行上面的程序,会出现如下错误:
1 | Cannot access a disposed context instance |
表示无法访问已经释放的context实例对象。
因为当调用完QueryStudents方法后,已经将TestContext对象销毁了,而在执行foreach遍历的时候,是需要通过TestContext链接数据库,从数据库中获取数据的,但是由于TestContext已经销毁了,所以无法再链接上数据库。因此程序出错了。
如果在QueryStudents方法中,采用ToList等方法把数据一次性加载到内存中就可以了,因为这时候在遍历的时候,只是遍历内存中的数据,而不需要再通过TestContext链接数据库。
如下代码所示:
1 | static IEnumerable<Student> QueryStudents() // 这里将方法的返回类型修改成了IEnumerable |
第二:多个IQueryable的遍历嵌套
在遍历一个IQueryable的时候,我们可能需要同时遍历另外一个IQueryable.IQueryable底层是使用DataReader从数据库中读取查询结果的,而且很多数据库是不支持多个DataReader同时执行的。
如下面代码所示:
1 | using (TestContext ctx =new TestContext()) |
执行上面的代码会出现如下的错误:
1 | There is already an open DataReader associated with this Connection which must be closed first |
这个错误的含义就是因为两个foreach都在遍历IQueryable,导致同时有两个DataReader在执行。
虽然可以在连接字符串中通过设置MultipleActiveResultSets=true开启“允许多个DataReader执行”,但是只有SQL Server支持MultipleActiveResultSets选项,其他数据库有可能不支持。因此建议采用“把数据一次性加载到内存”以改造其中一个循环的方式来解决
1 | using (TestContext ctx =new TestContext()) |
综上所述,在进行日常开发的时候,我们直接遍历IQueryable即可。但是如果方法需要返回查询结果或者需要多个查询嵌套执行,就要考虑把数据一次性加载到内存的方式,当然一次性查询的数据不能太多,以免造成过高的内存消耗。
KilgourNote:IQueryable底层是依靠DataReader实现的,在服务器向用户传输数据的时候要一直保持连接。
26、EF Core中的异步方法
我们知道,异步编程通常能够提升系统的吞吐量,因此如果实现某个功能的方法既有同步方法又有异步方法,我们一般应该优先使用异步
方法。保存上下文中数据变更的方法既有同步的在SaveChanges,也有异步的SaveChangesAsync,同样EF Core中其他的很多操作也都既
有同步方法又有异步方法。这些异步方法大部分是定义在Microsoft.EntityFrameworkCore命名空间下的
EntityFrameworkQueryableExtensions等类中的扩展方法,因此使用这些方法之前,请在代码中添加对Microsoft.EntityFrameworkCore命
名空间的引用。IQueryable的异步方法有AllAsync、AnyAsync、AverageAsync、ContainsAsync、CountAsync、FirstAsync、
FirstOrDefaultAsync、ForEachAsync、LongCountAsync、MaxAsync、MinAsync、SingleAsync、SingleOrDefaultAsync、SumAsync
等。这些方法都是IQueryable的扩展方法,同时都是立即执行的方法。
而GroupBy、OrderBy、Join、Where等这些非立即执行的方法则没有对应的异步方法,。
原因:我们知道异步方法主要用于耗IO的操作,避免一个操作长期占用一个线程,造成线程的阻塞,从而降低了系统的并发量。
而使用了异步操作以后,线程可以去处理其他的任务。例如:服务员不会等待你点完菜后才会去服务其他的客户,在你看菜单的时候,服务员可以服务其他的客户。所以,异步就是针对那些耗时操作,避免长期占用线程。
而Count,First等立即执行的方法,是要生成sql语句去操作数据库,是比较耗时IO操作,所以有异步方法。
而GroupBy,OrderBy,Where等方法,没有生成sql语句,没有去执行数据库的操作,没有消耗IO.这些方法的执行速度是非常快的。因而这些方法是不需要对应的异步方法的。
问题:遍历IQueryable的操作。如下代码所示:
1 | using (TestContext ctx =new TestContext()) |
以上代码是通过foreach遍历IQueryable,这是一个同步操作,是消耗IO的。
那么怎样进行异步的遍历IQueryable呢?
有两种方式:
第一种方式,如下所示:
1 | using (TestContext ctx =new TestContext()) |
这里我们使用了ToListAsync方法,在读取数据并且填充到List集合中的过程是采用异步方式完成的。而在遍历的时候是从List集合也就是内存中获取数据,这个过程就不涉及到IO的问题了。但是要注意的就是我们前面所讲的不要将太大的数据填充到内存中。
第二种方式,如下所示:
1 | var teachers = ctx.Teachers.Where(t => t.Id > 0); |
这里是通过AsAsyncEnumerable方法将IEnumerable转换成了异步的IEnumerable.
不过,一般情况下没有必要这么做,因为我们遍历的时候,内存中的数据也不是很大,速度也比较快。
如果后期在遍历数据的时候,确实出现了性能的瓶颈的时候,可以考虑以上的处理方式。
27、EF Core如何执行原生SQL语句
尽管EF Core已经非常强大,但是在某些场景一下,EF Core中的方法可能无法满足我们的需求。因此在少数场景下,我们仍然需要再EF Core中执行原生的SQL语句。
本小节,我们就来看一下,如何在EF Core中执行原生的SQL语句。
在EF Core中执行原生的SQL语句,有SQL非查询语句,实体类SQL查询语句,任意SQL查询语句等几种用法。
KilgourNote:
- 执行
SQL非查询语句:ExecuteSqlInterpolatedAsync(原生SQL语句) - 执行实体类
SQL查询语句:FromSqlInterpolated(原生SQL语句) - 执行任意
SQL查询语句:Ado.net的方式或者是Dapper等轻量级的ORM框架
27.1 执行SQL非查询语句
我们可以通过dbCtx.Database.ExecuteSqlInterpolated或者异步的dbCtx.Database.ExecuteSqlInterpolatedAsync方法执行原生的SQL非查询语句,下面举一个例子(在多对多项目中演示)。
下面执行的是一个insert语句,不是查询语句。
1 | Console.WriteLine("请输入老师名称"); |
通过上面的代码,我们可以看到ExecuteSqlInterpolatedAsync这个方法中使用了{uname}这样的插值方式为SQL语句提供参数值。
有同学可能会有疑问,这样字符串插值的方式不会有SQL注入攻击漏洞吗?答案是不会的,通过SQL Server Profile工具查看上面操作所生成的SQL语句,如下所示:
1 | insert into T_Teachers([Name]) values (@p0) |
我们可以看到,我们所写的{uname}这种内插变量,被翻译成了@p0这样的参数,而不是简单的字符串拼接。
因此这样的操作不会有SQL注入攻击的漏洞。
下面我们再来看一个例子,来体会一下ExecuteSqlInterpolatedAsync方法的使用
这里我们执行一个insert into ...select语句,该语句的含义是:先查询出数据,再把查询结果插入数据表中.
1 | var result = await ctx.Database.ExecuteSqlInterpolatedAsync($" insert into T_Teachers(Name) select Name from T_Teachers"); |
下面我们再来演示一下,看一下是否会有SQL注入攻击的问题。
1 | string uname = ";delete from T_Teachers;"; |
执行上面的代码,我们可以看到直接将delete语句插入到数据表中了。所以不存在sql注入的问题。
为什么没有sql注入的问题?
1 | string uname = "delete from T_Teachers;"; |
在上面的代码中,我们直接打印了sql变量,得到的结果是:
1 | insert into T_Teachers(Name) values (delete from T_Teachers;) |
这里从执行结果上看,是进行了字符串的拼接,是有sql注入的。
但是,为什么作为ExecuteSqlInterpolatedAsync方法的参数以后,就不存在sql注入的问题呢?
我们把鼠标指向ExecuteSqlInterpolatedAsync方法上,可以看到它需要的参数类型是FormattableString类型。
下面把上面的代码,修改一下,修改成如下的形式:
1 | string uname = "delete from T_Teachers;"; |
这里我们将sql变量的类型修改成了FormattableString类型。
同时打印了Format属性,该属性输出的内容是:
1 | insert into T_Teachers(Name) values ({0}) |
这里,我们可以看到我们在sql语句中写的插值表达式被占位符{0}给占用了。但是该占位符的值是多少呢?
我们再来看一下GetArguments方法的输出结果,该方法的输出结果是一个数组,所以这里我们使用string.Join方法将其分割成了字符串。打印的结果是:
1 | delete from T_Teachers; |
也就是会使用上面的参数替换掉占位符。
所以说:当一个C#字符串中包含内插值表达式,然后将该字符串赋值给了一个FormattableString类型的变量以后,编译器会把字符串中插值表达式以及赋值给插值表达式的值等内容构建成一个FormattableString对象,FormattableString对象中包含了插值表达式以及每个参数的值。这样在执行ExecuteSqlInterpolatedAsync这个方法的时候,就可以根据FormattableString对象的信息去构建参数化查询SQL语句。(解决sql注入攻击最好的方式就是参数化查询)
所以说,以后写sql语句就写成这种内插值的方式。
除了ExecuteSqlInterpolated、ExecuteSqlInterpolatedAsync方法之外,EF Core的ExecuteSqlRaw、ExecuteSqlRawAsync等方法也可以执行原生SQL语句,但使用这两个方法需要开发人员自己处理查询参数等问题,因此不推荐使用。
27.2 执行实体类SQL查询语句
如果我们要执行的SQL语句是一个查询语句,并且查询的结果也能对应一个实体类(注意:这里需要对应一个实体,有可能一个查询会关联多张表,这时候就不会对应一个实体,就不能使用这一小节所介绍的方法),就可以调用对应实体类的DbSet的(由于这里是对应一个实体,所以调用的就是DbSet中的方法)FromSqlInterpolated方法执行一个SQL语句,该方法的参数是FormattableString类型,因此同样可以使用字符串内插值传递参数、
案例:查询编姓张的学生信息(这个需求完成可以通过EFCore中的方法来实现,这里我们假设只能自己写SQL语句来实现,EF Core中的扩展方法满足无法满足这个需求)
1 | string s = "张%"; |
我们看FromSqlInterpolated没有异步的方法,只有同步的方法,原因是该方法返回的是IQueryable,也就是没有真正的执行查询操作,所以说该方法并没有IO的耗时操作。因此该方法不需要异步方法。
查看一下生成的sql语句,发现也是带参数的。
1 | select * from T_Students where Name like @p0 |
这里很明显进行了参数化的处理。
由于FromSqlInterpolated方法返回值是IQueryable类型的,因此我们可以在实际执行IQueryable之前,对IQueryable进行进一步的处理,例如使用Skip和Take方进行分页查询。
如下下面代码:
1 | string s = "张%"; |
以上代码就是就是跳过1条取2条记录。
当然,这里我们也可以对数据进行排序
1 | string s = "张%"; |
在上面的代码中,我们是将order by直接写到了sql语句中,执行上面的代码程序出错了。
我们通过SQL Server Profile来查看一下所生成的SQL语句,如下所示:
1 | SELECT [多].[Id], [多].[Name] |
这里发现,子查询中包含了order by,而在外层查询中通过offset fetch实现了分页操作。
但是问题是在SQLServer中order by是不能用在子查询中的。
这时候,正确的排序写法如下所示:
1 | string s = "张%"; |
执行上面的代码发现没有问题。
所以说,FromSqlInterpolated方法只能执行原生SQL语句写的逻辑,然后把分页,分组,排序,二次过滤,Include等其他的逻辑尽可能的使用EF Core的标准操作去实现。
例如:这里我们想关联T_Teachers表,就可以使用include
1 | string s = "张%"; |
FromSqlInterpolated方法也有使用的局限性:
第一:SQL查询必须返回实体类型对应数据表的所有列(返回部分列,会出现问题)
第二:查询结果集中的列名必须与属性映射到的列名匹配。
第三:SQL语句只能进行单表查询,不能使用Join语句进行关联查询,但是可以在查询后面使用Include方法进行关联数据的获取。
注意:如果是关联多表的查询,例如报表查询,这时候,并不会具体对应到某个实体,同时即使按照以上通过Include进行关联,生成的SQL语句有可能也不是高效的,这时候就需要自己写SQL语句。这种情况就不适合使用FromSqlInterpolated方法来进行查询
问题是,针对这种复杂的SQL语句,应该怎样执行呢?我们下一小节再进行讲解。
27.3 执行任意SQL查询语句
FromSqlInterpolated只能执行单实体类的查询,但是在实现报表查询的时候,SQL语句通常是非常复杂的,不仅要多表关联,而且返回的查询结果一般也都不会和一个实体类完整对应,因此我们需要一种执行任意SQL查询语句的方式。
1 | 存储过程好处:存储过程只需要在创建的时候编译,而普通的`sql`是使用一次编译一次,所以使用存储过程可以提高运行速度,减少流量交互。 |
EF Core中允许把一个视图或者一个存储过程映射为实体类,因此我们可以把复杂的查询语句写成视图或者存储过程,然后声明对应的实体类,并且在上下文中配置对应的DbSet属性。不过,目前大部分公司都不推荐编写存储过程(存储过程中包含了业务,数据库的压力增大,同时存储过程是不跨数据库的,不同数据库创建存储过程的语法是不一样的。),而推荐创建视图。但是项目的报表等复杂查询通常很多,因此对应的视图也会很多,我们就需要在上下文类中配置很多本质上不是实体类的“实体类”,这会造成项目中“实体类”的膨胀,也就是DbSet的膨胀,不利于项目的管理。
如下伪代码所示( T_Students可以理解成是一个视图):
1 | select Name from T_Students |
以上的查询没有对应一个具体的实体类,也就是没有和一张数据表对应的实体,而我们可以自己定义一个实体类
1 | class StudentInfo |
虽然,我们可以采用如上的做法,但是这样会导致DbSet的膨胀,非常不利于项目的管理。
像这种情况,我们可以直接使用原生的ADO.NET来进行数据的查询。
1 | // 注意这里的ctx还是DbContext对象 |
当然,以上的写法还是比较麻烦,还需要处理参数等情况。
所以可以使用Dapper这个轻量级的ORM框架。
1 | Install-Package Dapper |
1 | // 注意这里的ctx还是DbContext对象 |
这里在TestContext的范围外部定义一个StudentInfo类,如下所示:
1 | class StudentInfo |
注意:sql语句中as后面的别名,与StudentInfo中的属性保持一致。把查询的数据映射到了对应的属性上。
这里我们没有定义DbSet,只是定义了一个普通的类,这就是模型类,这样就不会出现DbSet的膨胀问题。
这里底层还是对Ado.net的封装。
关于Dapper的其他应用,大家可以查看文档自己学习。(https://www.cnblogs.com/gaoyongtao/p/15993191.html)
EF Core与Dapper可以混合使用,根据不同的情况选择不同的技术。
总结:
第一:一般Linq查询就够用了,尽量不用原生的sql,除非遇到前面所讲到的特殊情况
第二:非查询(insert ,update,delete)sql用ExecuteSqlInterpolatedAsync( )方法
第三: 针对实体的SQL查询用FromSqlInterpolated( )
第四:复杂sql查询用Ado.net的方式或者是Dapper等轻量级的ORM框架。
28、实体类变化的检测
KilgourNote:使用Linq查询语句查询出来的数据都处于DbContext的监视之下,因此查询出来的数据并不需要放入DbSet中也可以被SaveChangesAsync保存到数据库中。但是在Using(MyDbContext mc = new MyDbContext)中创建的新的模型对象则需要mc.Add()方法才能进入DbContext的监视中。
当我们修改从DbContext中查询出来的对象并调用SaveChanges方法的时候,EF Core会检测对象的状态变化,然后把变化后的数据保存到数据库中,但是实体类没有实现属性值改变的通知机制),EFCore是如何检测到实体类的这些变化的呢?
如下代码:
1 | var student =await ctx.Students.FirstOrDefaultAsync(); |
在上面的代码中,我们查询出了第一个学生信息,并且将学生的名字有张三修改成了张三三。
问题是:EF Core怎么就知道,我们赋值给Name属性新的值了呢(这里的Name属性就是一个普通的属性)?从而生成一个update语句进行更新呢?
因为,EF Core默认采用快照更改跟踪来实现实体类改变的检测。也就是说只要一个实体类对象和DbContext发生关系,例如上面的查询关系,或者是Add(添加)关系等,都默认会被DbContext跟踪。
怎么进行跟踪的呢?
EF Core会创建这个实体类的快照,当执行SaveChanges等方法的时候,EF Core将会把存储在快照中的值与实体类的当前值进行比较,以确定哪些属性值被更改了。
这个快照,我们可以理解成就是创建了一个副本(拍了一张照片)
EF Core还支持“通知实体类”“更改跟踪代理”等检测实体类改变的机制,但是这些机制用起来比较麻烦,带来的好处也不明显,因此我们一般都用默认的“快照更改跟踪”机制.
实体类的改变并不只有“属性值改变”这样一种情况,实体类中属性被删除,添加等也属于改变。对应着就有不同的状态,实体类有如下5种可能的状态。
1 | 已添加(Added):DbContext正在跟踪此实体类,但数据库中尚不存在此实体类。(新增实体,但是对应的数据还没有插入到数据库中) |
1 | 未改变(Unchanged):DbContext在跟踪此实体类,此实体类存在于数据库中,其属性值和从数据库中读取到的值一致,未发生改变。 |
1 | 已修改(Modified):上下文正在跟踪此实体类,此实体类存在于数据库中,并且其部分属性值已被修改。 |
1 | 已删除(Deleted):上下文正在跟踪此实体类,此实体类存在于数据库中,但在下次调用SaveChanges时要从数据库中删除对应数据。 |
1 | 分离(Detached):上下文未跟踪该实体类。 |
当执行SaveChanges的时候,EFCore会就会判断实体对象的状态,从而执行不同的操作。
1 | ·对于分离和未改变的实体类,SaveChanges会忽略它们。 |
下面我们来查看一下以上所说的这些状态。
这里,我们可以使用DbContext对象中的Entry方法获取一个实体类在EF Core中的跟踪信息对象EntityEntry.
EntityEntry中的State属性代表了实体的状态。并且通过DebugView.LongView属性我们可以看到实体类的状态变化信息。
下面我们来看一下代码示例:
1 | Student[] stus = ctx.Students.ToArray(); |
从上面程序的输出结果我们可以看出来,s1这个对象由于被修改了,因此状态是Modified, 而且Debug View中输出的是:
1 | Student {Id: 1} Modified |
编号为1的Student为Modified. Name的新值是张小三,原来的值是张三三
1 | Console.WriteLine("s2.state:" + entry2.State); |
s2对象从数据库中查询出来后没有任何修改,因此状态是Unchanged
s3对象被Remove方法标记为删除状态,因此对应的状态是Deleted
s4,s5两个对象都是新创建的对象,由于b4通过Add方法添加到了DbContext对象中,因此b4的状态是Added.
而s5这个新创建的对象没有与DbContext对象产生任何关系,所以s5状态是Detached.
由此可见,EF Core会跟踪实体类的状态,在执行SaveChanges的时候,EF Core会根据实体类状态的不同,生成对应的Update、Delete、Insert等SQL语句,从而把内存中实体类的变化同步到数据库中。
29、EF Core性能优化
我们知道EF Core会将我们所写的C#代码转换成对应的sql语句来操作数据库,如果我们使用EF Core不当,应用程序的性能和数据正确性会受到威胁,因此有必要对于如何更高性能地使用EF Core以及如何解决数据库并发问题进行讲解。
29.1 EF Core 优化之AsNoTracking
在上一小节中我们讲到了EF Core默认会对通过DbContext对象查询出来的所有实体类进行跟踪,以便于在执行SaveChanges的时候把实体类的改变同步到数据库中,DbContext对象不仅会跟踪对象的状态改变,还会通过快照的方式记录实体类的原始值,这是比较消耗资源的。因此,如果我们能够确认通过DbContext查询出来的对象只是用来展示,不会发生状态改变,那么可以使用AsNoTracking方法告诉IQueryable在查询的时候禁用跟踪,如下代码所示:
1 | List<Student> stus = ctx.Students.AsNoTracking().Take(3).ToList(); |
执行上面的代码,打印的entry1.State的值是Detached,也就是说使用了AsNoTracking查询出来的实体类是不被DbContext跟踪的。
这里我们即使调用SaveChanges方法也不会更新,不会生成update语句。
因此,在项目开发的时候,如果我们查询出来的对象不会被修改、删除等,那么在查询的时候,可以启用AsNoTracking,这样就能降低``EF Core`的资源占用。
29.2 实体状态跟踪的妙用
在使用EF Core的时候,我们可以借用状态跟踪机制,来完成一些特殊的需求。
由于EF Core 需要跟踪实体类的改变,因此如果我们需要修改一个实体类的属性值,一般都需要先查询出来对应的实体类,然后修改相应的属性值,最后调用SaveChanges保存修改到数据库中。如下代码所示:
1 | Student? s = await ctx.Students.FirstOrDefaultAsync(s=>s.Id == 1); |
上面的代码生成的SQL语句,
1 | SELECT TOP(1) [t].[Id], [t].[Name] |
可以看到,生成了select查询语句,同时也生成了update更新语句。
讲到这,有同学就可能已经想到了一个问题。如果直接执行sql语句的话,我们仅可以通过一条update语句就能完成数据的更新操作。
但是在EF Core中就需要两条SQL语句完成更新操作。
当然在EF Core中我们可以利用状态跟踪机制实现一条Update语句完成数据更新的功能。
如下代码所示:
1 | Student student = new Student { Id =1 }; |
通过SQL Server Profile工具只能看到只有1条update语句。
在上面的代码中,创建了Student对象,并且指定了要跟新的是编号为1的数据。这里是修改编号为1的学生姓名。
然后创建Entry对象。通过该对象中的Property方法获取Name属性的跟踪对象,然后通过设置IsModified为true,把Name属性设置为已修改,注意:只要实体类中的一个属性标记为已修改,那么这个实体类对应的状态也会被设置为已修改。最后执行SaveChanges方法进行修改,由于这里我们通过对象的Id属性的方式告诉了EF Core要更新哪条数据,所以会生成对应的update语句。
同样的,常规的EF Core开发中,如果要删除一条数据,我们也要将要删除的数据查询出来,然后在调用DbContext对象中的Remove方法把实体类标记为已删除,再执行SaveChanges方法的进行删除操作。
1 | Student? s = await ctx.Students.FirstOrDefaultAsync(s => s.Id == 1); // 这里会生成select查询 |
当然,在EF Core中我们也可以利用状态跟踪机制实现一条Delete语句完成数据的删除操作。
如下面代码所示:
1 | Student student = new Student { Id =9 }; |
在上面的代码中,我们创建了一个Student对象,并且指定了Id属性的值是9,也就是删除编号为9的这条记录,然后我们把实体类对应的State属性设置为了Deleted状态,来标记这个实体类为已经删除。
总结:通过上面的演示,我们知道借助于EF Core的实体类跟踪机制,我们可以让EF Core生成更加简洁的SQL语句,
大部分情况下,采用这种技巧带来的性能提升也是微乎其微的,毕竟“查询一下再删除”和“直接删除”的性能差别是很小的。
29.3 数据的批量删除,更新与插入
数据的批量插入:
1 | Student s =new Student{ Name="abc" }; |
采用如上的写法会生成3条insert语句。
如果采用如下写法呢?
1 | Student s =new Student{ Name="abc" }; |
这里虽然使用了AddRange方法,但是还是会生成3条sql语句,AddRange方法只是简化了Add方法的使用。
如果我们想一次性插入的数据量非常大的话,采用如上的方式性能就比较差了。
怎样解决呢?
我们可以使用ExecuteSqlInterpolatedAsync方法来执行原生的SQL语句。
在原生的sql语句中,有一种批量插入数据性能比较高的实现方式,就是通过 SqlBulkCopy方式
1 | https://learn.microsoft.com/zh-cn/dotnet/api/system.data.sqlclient.sqlbulkcopy?source=recommendations&view=dotnet-plat-ext-7.0 |
数据批量更新
EF Core 7中提供了批量更新的方法
将编号大于等于10的记录的学生名后面添加一个hello字符串
1 | var count = await ctx.Students.Where(s => s.Id >= 10).ExecuteUpdateAsync(e => e.SetProperty(a => a.Name, a => a.Name + "hello")); |
这里是先找到编号大于等于10的记录,然后调用ExecuteUpdateAsync方法,将Name属性的值修改后面添加hello这个字符串。
返回的就是修改数据表所影响的行数。
看一下生成的SQL语句
1 | UPDATE [t] |
数据批量删除
1 | var count = ctx.Students.Where(s=>s.Id>=10).ExecuteDelete(); |
上面的代码删除的是编号大于等于10的学生信息,返回的是影响的行数。
29.4 全局查询筛选器
EF Core支持在配置实体类的时候,为实体类设置全局查询筛选器,EF Core会自动将全局查询筛选器应用于涉及这个实体类型的所有Linq查询。
例如:我为Student实体类添加了一个全局查询筛选器, Num > 10
当我们写了如下查询的时候,也会在所生成的sql语句中自动添加全局查询筛选器中指定的过滤条件
1 | ctx.Students.Where(s=>s.Age = 18) |
以上查询生成的sql语句
1 | select * from T_Students where AGE = 18 and Num > 10 |
这个功能常见的应用场景就是软删除
基于“可审计性”“数据可恢复性”等需求的考虑,很多系统中数据的删除其实并不是真正的删除,数据其实仍然保存在数据库中,我们只是给数据库表增加一列“是否已删除”。当一行数据需要被删除的时候,我们只是把这条数据的“是否已删除”列的值改为“是”,数据仍然保存在数据库表中没有被删除。当进行数据查询的时候,在查询中我们把“是否已删除”列中为“是”的值过滤掉。这就叫作“软删除”。
在EF Core中,我们可以给对应实体类设置一个全局查询筛选器,这样所有的查询都会自动增加全局查询筛选器,被软删除的数据就会自动从查询结果中过滤掉。下面演示一下。
首先,我们给Student实体类增加一个bool类型的属性IsDeleted,如果对应的数据被标记为已删除,那么IsDeleted的值就是true,否则就是false。(这里在对多多项目中进行演示)
1 | public class Student |
在StudentConfig.cs文件中,指定默认值
1 | public class StudentConfig : IEntityTypeConfiguration<Student> |
执行一下迁数据移操作,注意:在【程序包管理器控制台】中选择【多对多项目】
1 | Add-Migration IsDeleted |
这时候在T_Students表中添加了IsDeleted 字段。
下面进行软删除的操作。
1 | var studentInfo = await ctx.Students.Where(s=>s.Id==1).FirstOrDefaultAsync(); |
这里就是把编号为1的记录的IsDeleted字段的值设置为true,表示的就是软删除了这条记录。
下面,我们进行查询,如下所示:
1 | var students = ctx.Students; |
这里,如果我们如果执行上面的查询,会将已经【软删除】的记录也给查询出来。
如果,我们不想把已经软删除的记录查询出来,可以给定查询的条件,如下所示:
1 | var students = ctx.Students.Where(s=>s.IsDeleted!=true ); //这里添加了过滤条件 |
但是每次写这个过滤的条件是比较麻烦的,这里我们可以在StudentConfig.cs这个配置文件中添加如下的配置,如下所示:
1 | public void Configure(EntityTypeBuilder<Student> builder) |
下面,我们再来看一下如下的查询。
1 | var students = ctx.Students; |
在以上的查询中我们并没有指定过滤的条件,但是这里查询的学生姓名中并不包含已经软删除的记录。
即使我们进行如下的查询,也会添加上以上配置的过滤条件。
1 | var students = ctx.Students.Where(s=>s.Name.Contains("张")); |
在上面的程序中,我们指定的过滤条件是查询一下学生名称中是张姓的学生,虽然数据表中的第一条记录也是满足条件的,但是由于第一条记录已经被软删除了,所以执行上面的查询不会查询出第一个学生。
看一下生成的SQL语句,如下所示:
1 | SELECT [t].[Id], [t].[IsDeleted], [t].[Name] |
可以看到在以上的sql语句中,添加了对已经软删除记录的过滤条件。
这里有一个问题:如果我们想查询出所有已经软删除的记录应该怎样实现呢?
你可能会想到采用如下的查询方式,如下所示:
1 | var students = ctx.Students.Where(s=>s.IsDeleted==true); |
执行上面的代码发现没有查询到任何的结果。
查看一下所生成的sql语句,如下所示:
1 | SELECT [t].[Id], [t].[IsDeleted], [t].[Name] |
在上面的sql查询条件中,发现查询条件比较奇怪,这里是查询IsDeleted不等于1(1这个了表示的就是true)或者是不等于null,并且IsDeleted等于1.
很明显根据这个条件无法查询出任何的记录。
这时候,我们应该怎样进行处理呢?
1 | var students = ctx.Students.IgnoreQueryFilters().Where(s=>s.IsDeleted==true); |
在上面的查询中我们使用了IgnoreQueryFilters这个方法,该方法的作用就是在进行查询的时候,忽略掉全局过滤筛选。
运行上面的程序,发现能够查询出已经软删除的记录数据。
可以看一下所生成的sql语句,发现全局查询筛选器中的过滤条件并没有添加。
当然,这里仅仅是在当前所指定的查询中忽略掉了全局查询筛选器。如果在别的针对当前Student实体类的查询中还是会添加全局查询筛选器。
注意:由于这里针对Student实体类查询过滤的时候,都会自动带上我们所添加的全局查询筛选器,所以可以考虑给IsDeleted添加索引,来提升查询的效率。当然,这里一定是在出现了性能问题的时候,才考虑添加索引。
29.5 悲观并发控制
什么是并发问题?
先来看一个问题:统计文章的点赞量。
并发控制指的就是避免多个用户同时操作资源造成的并发冲突的问题。
当然,解决并发问题的最好解决方案,是通过非数据库解决方案,性能高。例如通过redis队列,操作内存
在数据库中解决并发问题也是可以的,但是相对来讲性能低,因为必进是磁盘IO
这里,我们先讲解数据库层面怎样解决并发问题,关于数据库层面有两种策略,分别是悲观策略与乐观策略。
悲观并发控制一般采用行锁、表锁等排他锁对资源进行锁定,确保同时只有一个使用者操作被锁定的资源
因为不同类型的数据库对于悲观并发控制的实现差异很大,所以EF Core没有封装悲观并发控制,需要开发人员编写原生SQL语句
下面我们演示一下:
创建一个悲观并发控制控制台项目
安装EFCore操作数据库对应的包
1 | <ItemGroup> |
创建一个House.cs实体类,代码:
1 | public class House |
创建一个HouseConfig.cs文件,代码:
1 | public class HouseConfig : IEntityTypeConfiguration<House> |
创建MyDbContext.cs,代码:
1 | public class MyDbContext:DbContext |
执行数据库的迁移操作
在[程序包管理器控制台]中选择对应的控制台项目,执行
1 | Add-Migration Init |
然后在数据表中,录入测试数据。
下面实现代码,在Program.cs文件中添加如下代码:
1 | Console.WriteLine("请输入你的名字"); |
下面,我们找到bin目录,直接执行对应的exe程序,开启两个窗口,模拟两个用户抢房子(在这之前,一定要将项目重新生成一下)
在第-一个窗口中输入zhangsan(不要敲回车键),在另外一个窗口中输入lisi,然后再返回到第一个窗口中按下回车键,同时在第二个窗口中也按下回车键,在等待了一段时间后,两个窗口都会显示用户抢到了房子,而在数据库中,存储的只是lisi。这就是并发冲突的问题。
下面看一下具体的解决
KilgourNote:悲观并发控制的本质就是给需要改变的字段加锁,以保证每一次访问都是最新的数据 也就是使用事务给数据库字段加锁以达到目的 transaction-事务
下面的代码就是悲观并发控制的代码:
1 | Console.WriteLine("请输入你的名字"); |
悲观并发控制的使用比较简单,只要对要进行并发控制的资源加上锁即可。但是这种锁是独占排他的,如果系统并发量很大,锁会严重影响性能(一个操作加锁,其他操作都需要等待),如果使用不当,甚至会导致死锁。因此,对于高并发系统,要尽量优化算法,比如调整逻辑或者使用NoSQL等,尽量避免通过关系数据库进行并发控制。如果必须使用数据库进行并发控制,尽量采用乐观并发控制。
29.6 乐观并发控制
以T_Houses表为例,由于可能有多个操作者并发修改Owner列
在更新Owner列的时候,我们把Owner列更新前的值也放入Update语句的条件中,SQL语句如下:Update T_Houses set Owner=新值 where Id=1 and Owner=旧值。
如下示例代码:
RowVer = 0x00000000000007D6
update T_Houses set Owner=’zhangsan’ where Id=1 and RowVer = 0x00000000000007D7
Update T_Houses set Owner=’lisi’ where Id=1 and RowVer =”0x00000000000007D6”
1 | update T_Houses set Owner='zhangsan' where Id=1 and Owner="" //影响一行 |
即使并发,在某个时间点上只有一个用户进行更新,例如zhangsan抢到了房间。
1 | Update T_Houses set Owner='lisi' where Id=1 and Owner="" // 影响0行数 |
lisi去抢房子的时候,Owner的值已经不是空了,而是zhangsan,所以并发修改失败。
以上就是乐观并发控制的实现原理。
通过上面所举的例子,我们可以看到Owner这个列是被并发操作影响的列,所以这个列我们也可以称作并发令牌列。
也就是说,并发令牌列通常就是被并发操作影响的列。
1 | 总结:这样,当执行Update语句的时候,如果数据库中的Owner值已经被其他操作者更新,那么where语句的值就会为false。因此这条Update语句影响的行数就是0,EF Core就知道“发生并发冲突了”,此时SaveChanges方法就会抛出DbUpdateConcurrencyException异常。 |
问题:怎样将Owner 这个列设置为并发令牌呢?
EF Core中,我们只要把被并发修改的属性使用IsConcurrencyToken设置为并发令牌即可
下面演示
新创建一个控制台项目,安装EFCore操作数据库所需要的包
同时,将拷贝上一个控制台项目中的文件
修改HouseConfig.cs文件
1 | namespace 乐观并发控制 // 修改了命名控制 |
MyDbContext.cs修改一下命名空间。
House.cs修改一下命名空间。
Program.cs文件中的代码(以下代码,是根据最开始的代码进行改造的)
1 | using Microsoft.EntityFrameworkCore; |
KilkgourNote:
代码解释
以下是这两行代码的逐步解释:
var message = ex.Entries.First();
- 这里,
ex.Entries是一个IReadOnlyList<EntityEntry>,包含所有导致并发冲突的实体条目。First()方法返回列表中的第一个条目,这个条目是一个EntityEntry对象,表示发生并发冲突的实体。var value = message.GetDatabaseValues()!.GetValue<string>("Ower");
message.GetDatabaseValues()方法从数据库中获取该实体的最新值,并返回一个PropertyValues对象。GetValue<string>("Ower")方法从PropertyValues对象中获取名为Ower的属性的值,并将其转换为string。使用场景
这种处理方法在并发冲突的情况下非常有用,例如多个用户同时尝试更新同一个记录时:
- 用户 A 读取记录,开始编辑。
- 用户 B 读取相同的记录,开始编辑。
- 用户 A 保存更改,这会成功。
- 用户 B 尝试保存更改,但因为用户 A 已经修改了记录,导致并发冲突。
在用户 B 捕获到
DbUpdateConcurrencyException后,可以通过GetDatabaseValues()获取数据库中的最新值,并决定如何处理冲突,例如通知用户冲突情况或重新加载数据。
总结:乐观并发控制则允许多个使用者同时操作同一个资源,通过冲突的检测避免并发操作。
和悲观并发控制的代码相比,乐观并发控制不需要显式地使用事务,而且不需要使用数据库锁,我们只要捕捉保存更改时候的DbUpdateConcurrencyException异常即可。我们可以通过DbUpdateConcurrencyException类的Entries属性获取发生并发修改冲突的EntityEntry对象,并且通过EntityEntry类的GetDatabaseValuesAsync获取当前数据库的值.
注意:以上操作不需要数据库迁移
29.7 乐观并发控制2
我们可以通过把并发修改的属性设置为并发令牌的方式启用乐观并发控制。但是有时候我们无法确定到底哪个属性适合作为并发令牌,比如程序在不同的情况下会更新不同的列或者程序会更新多个列,在这种情况下,我们可以使用设置一个额外的并发令牌属性的方式来使用乐观并发控制。
如果使用Microsoft SQL Server数据库,我们可以用一个byte[]类型的属性作为并发令牌属性,然后使用IsRowVersion把这个属性设置为RowVersion类型,这个属性对应的数据库列就会被设置为ROWVERSION类型。对于ROWVERSION类型的列,在每次插入或更新行时,Microsoft SQL Server会自动为这一行的ROWVERSION类型的列生成新值(只要更新这一行中的任意字段的值,ROWVERSION类型的列就会生成新的值)。
下面演示如何在Microsoft SQL Server中通过额外的ROWVERSION类型列进行乐观并发控制。首先,我们定义包含一个byte[]类型属性的House类
这里我们直接在上一小节创建的控制台项目中进行修改。
修改House.cs中的代码
1 | namespace 乐观并发控制 |
下面,我们对House实体类进行配置,对RowVer属性设置IsRowVersion
修改HouseConfig.cs中的代码,如下所示:
1 | namespace 乐观并发控制 |
下面执行数据库的迁移,这里为了方便测试,我们重新创建一个新的数据库。
所以修改一下MyDbContext.cs中的数据库连接字符串
1 | Add-Migration Init2 |
数据库迁移完成以后,打开数据库表的结构,查看RowVer字段类型,发现是timestamp 类型。
在SQL Server中,timestamp和rowversion是同一种类型的不同别名,效果是一样的,那就是每次对一行数据进行更新的时候,timestamp列的值都会自动更新(数据库来进行维护),因此timestamp列是一个非常好的并发令牌列。
这里可以在SQLSERVER中进行演示,看一下每次修改一个字段的值,RowVer字段的值是否发生变化。
注意:Program.cs文件中的代码不需要修改,与上一小节的代码是一样的。
总结:
1 | 乐观并发控制能够避免悲观锁带来的性能下降、死锁等问题,因此推荐使用乐观并发控制而不是悲观锁。如果有一个确定的字段要被进行并发控制,使用IsConcurrencyToken把这个字段设置为并发令牌即可;如果无法确定唯一的并发令牌列,可以引入一个额外的属性并将其设置为并发令牌,并且在每次更新数据的时候,手动更新这一列的值;当然,如果用的是Microsoft SQL Server数据库,我们也可以采用RowVersion列,这样就不用开发人员手动更新并发令牌列的值了(数据库来进行维护)。 |
30、表达式树
30.1 什么是表达式树
表达式树(expression tree)是用树形数据结构来表示代码逻辑运算的技术,它让我们可以在运行时访问逻辑运算的结构。表达式树在.NET中对应Expression<TDelegate>类型。
1 | Expression<Func<Book,bool>> el = b =>b.Price > 5; |
编译器在分析上面的表达式的时候,会分析出上面是一个比较的运算。然后构成如下的表达式树
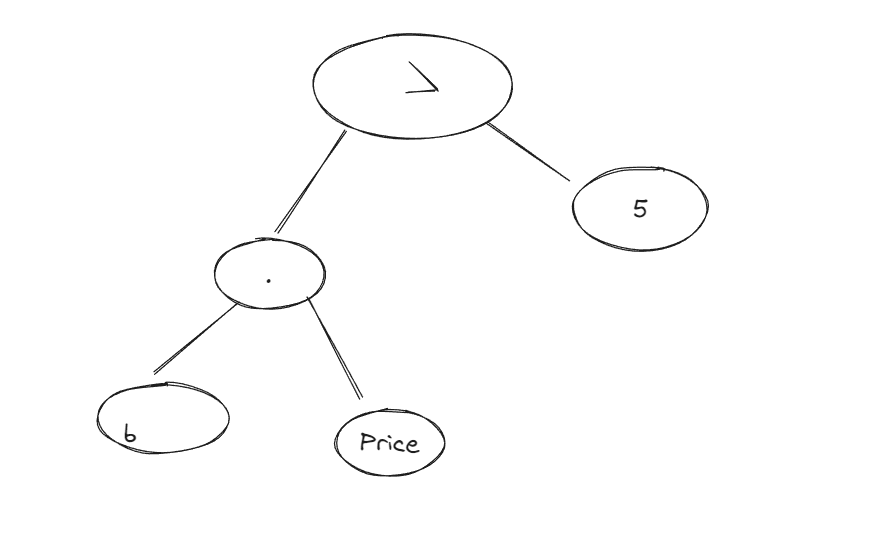
下面在对上图中的表达式树进行遍历(深度遍历),从而构成对应的SQL语句。
在Program.cs中查看一下
1 | Expression<Func<Book,bool>> el =b.Price >5 |
如果采用如下的写法:
1 | Func<Book,bool> el =b.Price >5 |
语法上没有任何问题,但是并不会生成表达式树。
1 | Expression<Func<Book,bool>> el =b.Price >5 |
总结:Expression对象存储了运算逻辑,它把运算逻辑保存成抽象语法树(AST),可以在运行时动态获取运算逻辑,而普通委托则没有。